

# coding=utf-8
# noinspection PyUnresolvedReferences
import parsel
import requests
# noinspection PyUnresolvedReferences
import re
from lxml import etree
url = 'https://zhidao.baidu.com/question/2207469534762529468.html'
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
response = requests.get(url)
xml = response.content
data = etree.HTML(xml).xpath('//*[@accuse="aContent"]')
print(data)
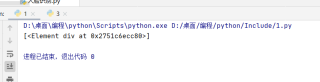
获取到的内容是这样的如何才能获取到需要的内容









