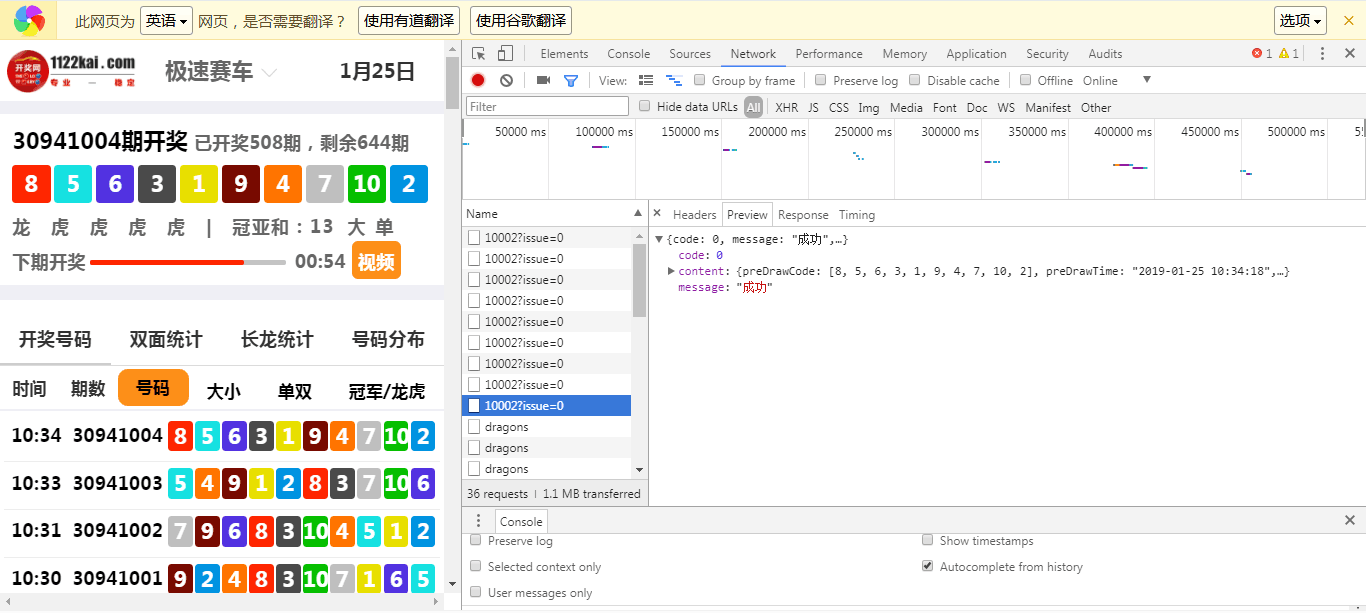
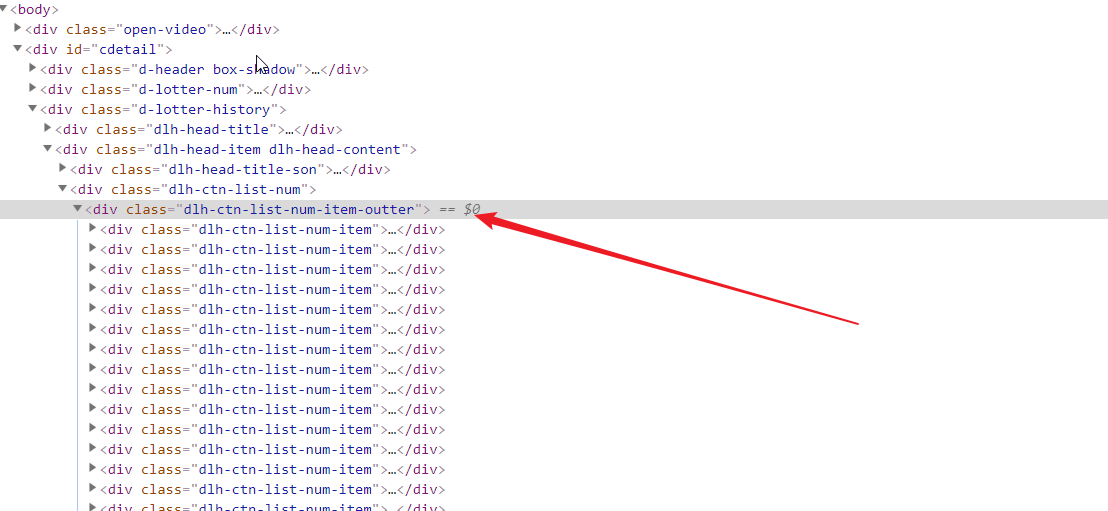
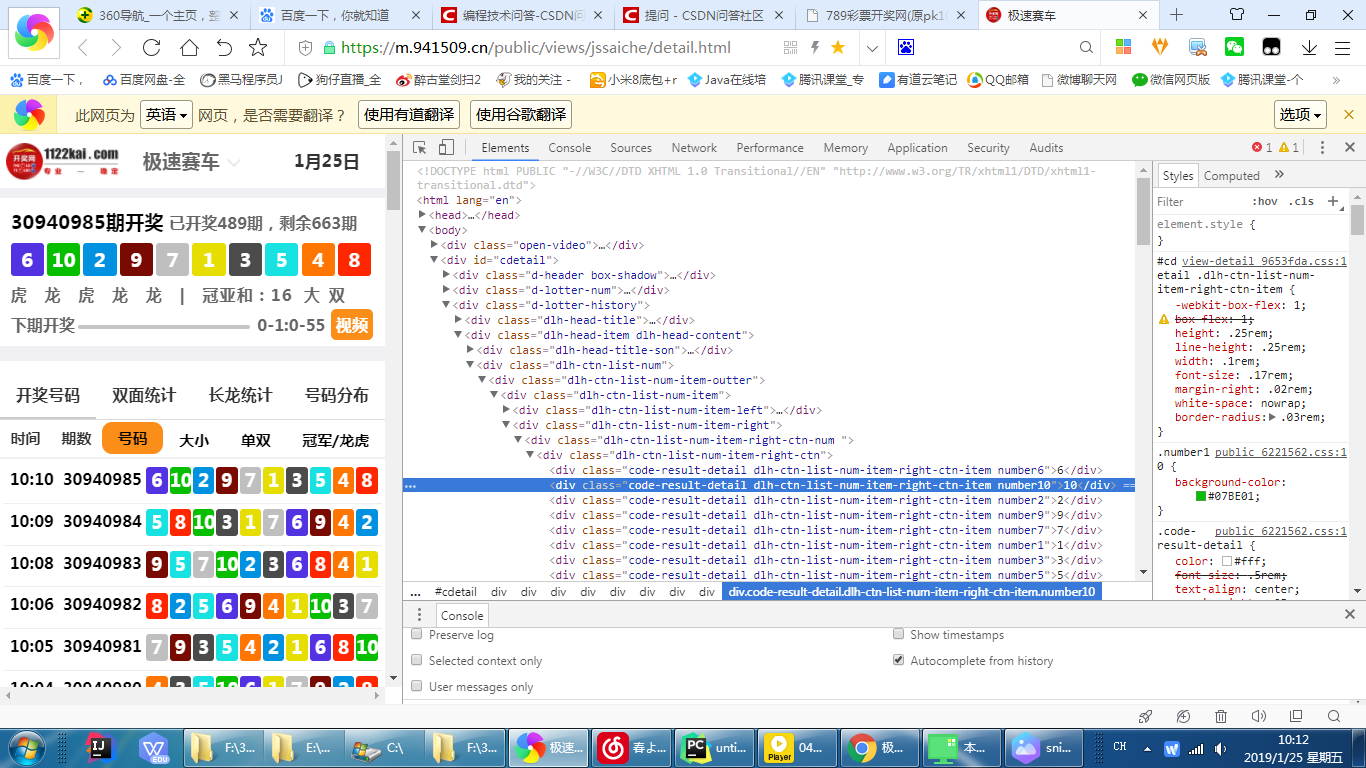
怎么爬取最近5期数字? 爬的是空壳[],帮忙看一下哪里写的不对请指教
是不是json格式,需要动态Ajax加载页面爬
import re
import requests
def parse_page(url):
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
}
response = requests.get(url,headers)
text = response.text
titles = re.findall(r'
.*?
print(titles)
# dynasties = re.findall(r'
poem_tags = re.findall(r'
print(poem_tags)
(.*?)
',text,re.S) #dlh-ctn-list-numx dlh-ctn-list-num-item-outterprint(titles)
# dynasties = re.findall(r'
.*?(.*?)',text,re.S)
# authors = re.findall(r'
.*?(.*?)',text,re.S)
# poem_tags = re.findall(r'
(.*?)
',text,re.S) #dlh-ctn-list-num-item-rightpoem_tags = re.findall(r'
(.*?)
', text, re.DOTALL)print(poem_tags)
def main():
url = "https://m.941509.cn/public/views/jssaiche/detail.html"
parse_page(url)
if name == '__main__':
main()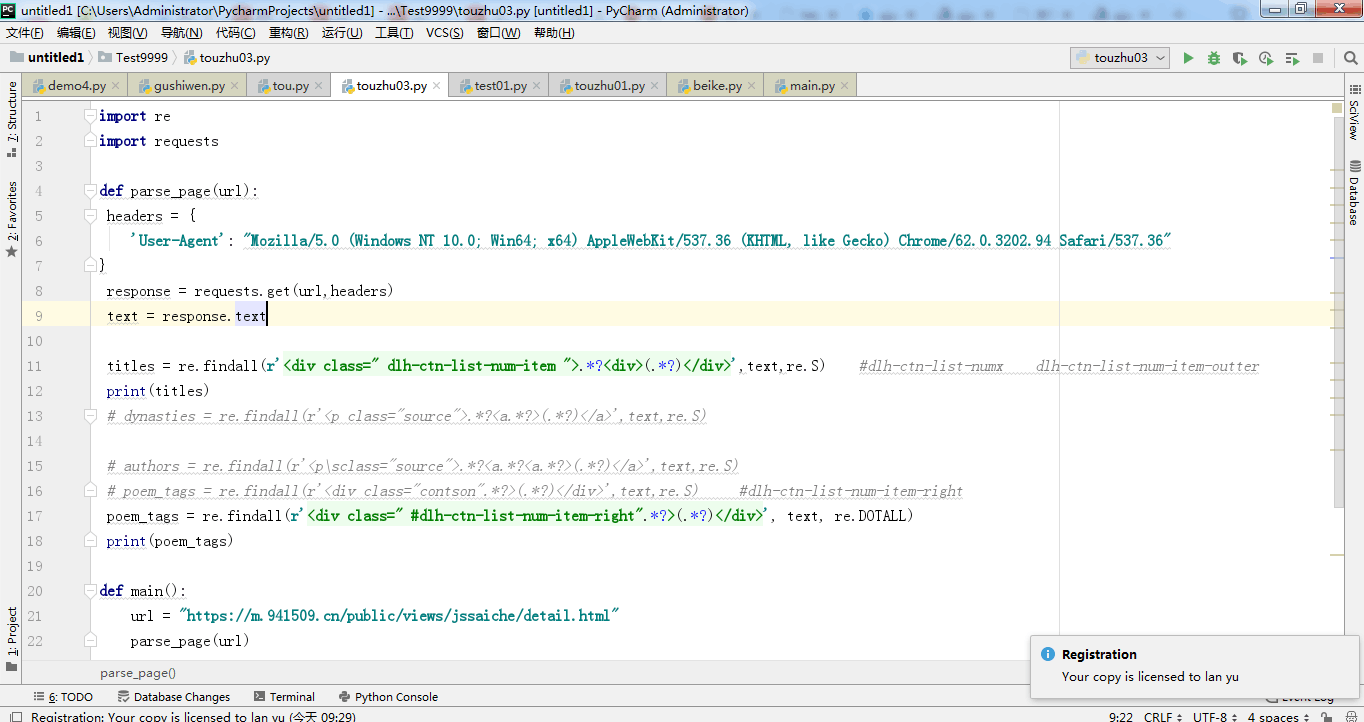
爬的是空壳[]
动态Ajax加载页面怎么爬