之前jdk的安装目录为/usr/local/jdk1.7.0_80,后来新建了一个文件夹jdk把jdk1.7.0_80放进文件夹里了/usr/local/jdk/jdk1.7.0_80
/etc/profile的JAVA_HOME也改了也source了_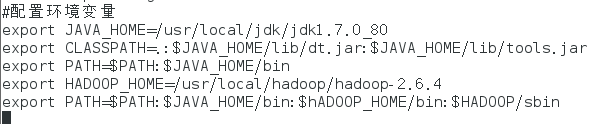
which java也对

还有hadoop-env.sh的JAVA_HOME也改了

我先start-dfs.sh,没问题
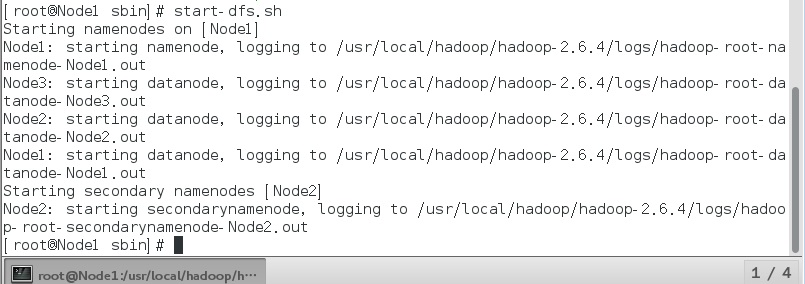
再start-yarn.sh就报错了
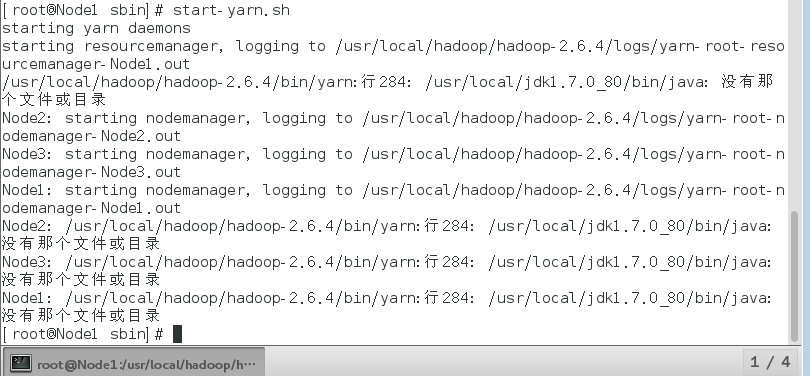
请大佬指导

之前jdk的安装目录为/usr/local/jdk1.7.0_80,后来新建了一个文件夹jdk把jdk1.7.0_80放进文件夹里了/usr/local/jdk/jdk1.7.0_80
/etc/profile的JAVA_HOME也改了也source了_
which java也对
还有hadoop-env.sh的JAVA_HOME也改了
我先start-dfs.sh,没问题
再start-yarn.sh就报错了
请大佬指导
 分享
分享
