

程序目的是:爬取文本
需要爬取的网页源代码的结构是这样的:
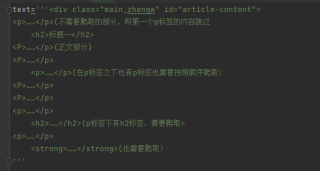
目的是:跳过第一个标签(不知道怎么跳过),读取接下来的所有标签内容(按照顺序)。
本人原先代码:

使用xpath,爬取p标签的内容,那么它会爬取所有的P标签,和跳过所有的h2和strong标签,就算我写上定位到h2和strong标签的xpath规则,它也只会一次性返回h2或者strong的列表,而我需要它按照网页顺序进行爬取,请问怎么样做到
最后整理:1.如何跳过第一个p标签
2.如何按照顺序把div里的文本内容爬取出来









