




爬虫爬取tr中的td内容,我的代码之前可以爬另一个几乎一样的网页,不知道为什么这个就不行了
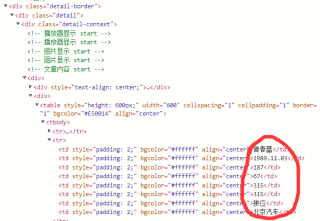

爬虫爬取tr中的td内容,我的代码之前可以爬另一个几乎一样的网页,不知道为什么这个就不行了
 分享
分享 分享
分享 import requests
from bs4 import BeautifulSoup
headers = {
"user-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
url = 'http://www.volleychina.org/chnwvt2015.htmll'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
tr_list = soup.select('.detail-context tr')
print(tr_list)
f = open('./女排名单/2015女排名单.txt', 'w+', encoding='utf-8')
for tr in tr_list:
td_list = tr.select('td')
# name = td_list[0].text.strip()
# birthtime=td_list[1].text.strip()
# height=td_list[2].text.strip()
# smash=td_list[4].text.strip()
# block=td_list[5].text.strip()
# position = td_list[6].text.strip()
# province=td_list[-1].text.strip()
附代码的话会被判断成违规
 系统已结题
3月15日
系统已结题
3月15日 已采纳回答
3月8日
创建了问题
3月8日
已采纳回答
3月8日
创建了问题
3月8日












