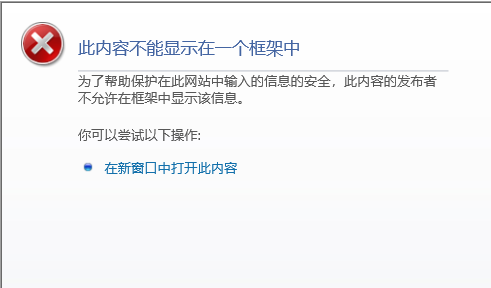
最近在学习python爬虫,试着爬取一些网站信息后,想要爬取学校教务处网站,学校查成绩的入口只有校园网可以进,但是之前有人做出来了爬虫可以爬取教务处成绩,我也想做出来。网站在IE和Chrome浏览器下都显示此内容无法在框架在一个框架中,新窗口打开也不行,查网上一些资料说用beautiful soup4解析网站即可,但是依然不行,出现了上面那句英文。scr的连接是http://1.1.1.2/disable/disable.htm有没有大神指点下。。。。。
代码如下:
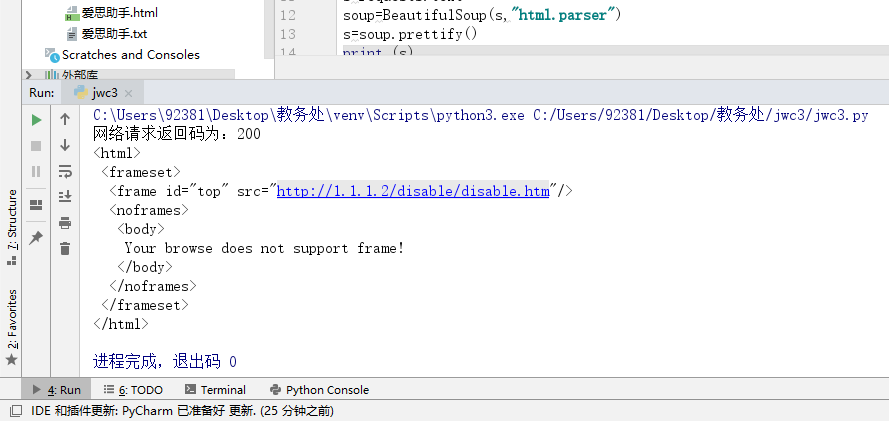
import requests;
import logging;
from bs4 import BeautifulSoup;
import os;
url = "http://jwcweb3.wit.edu.cn";
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"};
logging.captureWarnings(True);
requests = requests.get(url=url,verify=False,data=header);
print("网络请求返回码为:%d"%requests.status_code);
requests.encoding=requests.apparent_encoding
s=requests.text
soup=BeautifulSoup(s,"html.parser")
s=soup.prettify()
print (s)

爬虫使用beautiful soup4时遇到Your browse does not support frame!,新手求解决

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 你知我知皆知 2024-08-08 06:04关注
你知我知皆知 2024-08-08 06:04关注以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
您的问题主要涉及到如何正确地使用Beautiful Soup来处理网页上的HTML结构。您提到的问题可能是由于浏览器对框架元素的支持不足导致的。下面是一些建议来解决这个问题:
1. 使用
lxml替换bs4lxml是一个比BeautifulSoup更现代、功能更强的库,它提供了更多的高级特性,包括更好的跨域支持。from lxml import html url = "http://1.1.1.2/disable/disable.htm" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36', } response = requests.get(url, headers=headers) if response.status_code == 200: tree = html.fromstring(response.content) else: print(f"Failed to get content with status code {response.status_code}")2. 检查浏览器兼容性
确保您的浏览器支持HTML5标准,并且没有阻止框架元素的渲染。例如,在Firefox中禁用
Frame Resizing(设置Content Security Policy),或者在Google Chrome中启用Web Inspector以查看是否允许框架元素。3. 使用不同的代理服务器或反向代理
有时候,使用不同的代理服务器或反向代理服务可以帮助绕过某些防火墙限制。
4. 检查网络环境
如果可能的话,请尝试在另一个网络环境下运行程序,因为网络环境也会影响浏览器的行为。
5. 使用其他方法获取页面内容
如果上述方法都无法解决问题,您可以考虑使用其他技术从页面上提取所需的内容,比如通过JavaScript API或者手动下载页面源代码。
注意事项
- 在进行任何更改之前,请确保备份所有重要的文件。
- 尽管我尽力提供解决方案,但具体操作可能因浏览器版本、操作系统等不同而有所差异。
- 在实际应用中,最好先测试并确认方案的有效性,避免直接修改生产环境中的代码。
希望这些建议能帮到您!如果您有更多关于编程、网络或浏览器相关的问题,请随时提问。
解决 无用评论 打赏举报 分享
- 2021-01-21 16:58文章目录Beautiful Soup4 简介Beautiful Soup4 解析器Beautiful Soup4 安装Beautiful Soup4 解析器安装Beautiful Soup4 简单使用Beautiful Soup4 四大对象TagNavigableStringBeautifulSoupComment Beautiful Soup4 ...
- 2020-12-22 04:23python爬虫模块Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下: Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能...
- 2020-12-30 20:46Beautiful Soup使用时,一般可以通过指定对应的name和attrs去搜索,特定的名字和属性,以找到所需要的部分的html代码。 但是,有时候,会遇到,对于要处理的内容中,其name或attr的值,有多种可能,尤其是符合某一...
- 2021-01-21 17:53本文实例讲述了Python3爬虫学习之爬虫利器Beautiful Soup用法。分享给大家供大家参考,具体如下: 爬虫利器Beautiful Soup 前面一篇说到通过urllib.request模块可以将网页当作本地文件来读取,那么获得网页的html...
- 2020-09-10 14:35Code皮皮虾的博客 文章目录1、简介2、解析库3、讲解3.1、Tag(标签选择器)3.2、标准选择器(find、find_all)3.2.1、find_all()3.2.2、find()3.3、Select选择器4、实战 1、简介 Beautiful Soup 是一个可以从HTML或XML文件中提取...
- 2018-09-29 21:50fengzhen8023的博客 一、Beautiful Soup4简介 这个第三方库可以帮助我们来处理请求下来的HTML页面中的数据,如果你之前有过前端开发的经验或者是熟悉HTML标记语言和CSS语言的话,那么基本上可以无缝对接地使用这个第三方库来帮助你处理...
- 2022-08-18 23:58谦虚且进步的博客 python爬虫之beautifulsoup的使用
- 2022-09-19 23:08最后,Beautiful Soup还可以与其它库(如requests和lxml)结合使用,提升爬虫的效率和灵活性。例如,使用`lxml`解析器可以提高解析速度,而requests库则方便进行HTTP请求。 总的来说,Beautiful Soup作为Python爬虫...
- 2021-07-22 17:14孤寒者的博客 万字博文教你python爬虫Beautiful Soup库【详解篇】
- 2024-09-05 02:56qq_37836323的博客 Beautiful Soup是一个强大的Python库,专门用于从HTML和XML文件中提取数据。它的名字来源于"tag soup"(标签汤),暗示了它能够处理格式不规范的...通过本文的介绍和示例,你应该已经掌握了Beautiful Soup的基本用法。
- 2023-02-14 08:10内容概要: Beautiful Soup是Python中的一个强大...Beautiful Soup有很多优点,如能够按照标签、属性、字符串等方式检索文档,可以修改文档的编码、属性等,在Python爬虫开发中,Beautiful Soup是非常重要的工具之一。
- 2022-10-04 16:12the丶only的博客 Python 爬虫正则表达式和re库在爬虫过程中,可以利用正则表达式去提取信息,但是有些人觉得比较麻烦。因为花大量时间分析正则表达式。这时候可以用高效的网页解析库Beautiful Soup。Beautiful Soup 是一个HTML/XML ...
- 没有解决我的问题, 去提问

