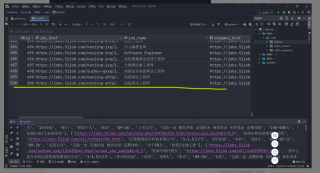
python爬虫时爬取了1000条数据,存入sqlite数据库中只能存500条,数据表中只显示了500条!我分两次各存500条,第一次操作OK,第二次怎么都不行,还有我试了一下将后面500条存入新建的表中,爬取内容没问题!但是存入数据库存不进去!这是啥情况?有人知道吗?怎么解决?
爬取51job网站的数据
1.获取网页
2.提取数据(标签定位+正则解析)
3.保存数据到sqlite数据库
#以下是代码
import json
import re
import sqlite3
import urllib.error # 导入urllib库的请求、错误提示、解析模块
import urllib.request
from urllib import parse
# 全局变量
# 对于英文关键字来说,使用parse模块进行一次/二次编码都没啥变化!主要针对中文关键字!
# 51job的中文关键字需要二次编码!
# keyword="ui"
keyword = "大数据"
# keyword=input("请输入关键字:")
b1 = parse.quote(keyword) # 先进行一次编码
b2 = parse.quote(b1) # 进行二次编码
def main():
print("------开始爬取网页------")
# 1.获取网页+提取/解析数据
# url后面的参数不要加!for循环来添上!
baseUrl = "https://search.51job.com/list/070200,000000,0000,00,9,99," + b2 + ",2,"
data_list = getData(baseUrl) # 提取要爬取网页的所有数据
print(data_list)
# print(len(data_list))
# 2.保存数据
dbPath = r"51job.db"
saveDB(data_list, dbPath)
# 获取网页+解析/提取数据
# 爬取网页并一个个的解析数据
# [注意]:有些网站不要一直去爬取访问网页,否则时间次数多了会封禁IP导致无法爬取该网址。所以爬完需要的网页后可以保存在一个html文件中,记得注释掉爬取网页代码!
# 然后再解析需要的数据
def getData(baseUrl):
# 爬取1000条数据,分20页,每页50条数据
datalist = [] # 保存爬取的所有数据
for i in range(11, 21):
# 分析要爬取的网址规律,拼接出网址方便循环爬取多个网页
askUrl = baseUrl + str(i) + ".html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare="
# print(askUrl)
# 爬取网页/异步请求url的内容
html = getHtml(askUrl) # 得到html网页内容
# print(html)
str_data = str(html) # 变成字符串格式
# 正则表达式解析出数据 (正则表达式一定要写好!不然无法筛选出需要的数据!)
findData = re.findall(r'"engine_jds":(.*),"jobid_count"', str_data)[0] # 得到的是一个字符串数据
findData = findData.replace("\\", "") # 替换掉多余字符
# print(findData)
# 要想提取出json格式数据中的每一项我们所需的数据,就必须将字符串用json的loads()方法转换成json格式(即字符串转成字典形式)方便提取数据!
json_data = json.loads(findData) # 是一个列表,每一项都是字典,字典里保存着每一个工作岗位的相关数据
# print(json_data)
for item in json_data:
data = [] # 保存一个工作的相关信息
# print(item)
# print(item["job_href"],item["job_name"])
data.append(item["job_href"])
data.append(item["job_name"])
data.append(item["company_href"])
data.append(item["company_name"])
data.append(item["providesalary_text"])
# 从attribute_text属性的属性值中提取出各个数据
info = item["attribute_text"] # 是个列表
# print(len(info))
data.append(info[1]) # 将经验信息追加到data中
if len(info)==4: # 有些公司可能没有学历信息,所以要分情况判断!否则会报错list列表下标超出范围!
data.append(info[2]) # 将学历信息追加到data中
else:
data.append("")
if len(info)==4: # 有些公司可能没有招聘人数信息,所以要分情况判断!否则会报错list列表下标超出范围!
data.append(info[3]) # 将招聘人数信息追加到data中
else:
data.append("")
data.append(item["workarea_text"])
data.append(item["updatedate"])
data.append(item["companytype_text"])
data.append(item["jobwelf"])
data.append(item["companysize_text"])
data.append(item["companyind_text"])
# print(data)
datalist.append(data)
# print(datalist)
return datalist
# 获取指定url地址的网页内容(爬取一个网页)
def getHtml(askUrl):
headers = { # 模拟浏览器向51job服务器发送请求
"User-Agent": "Mozilla/5.0 (Windows NT 10.0;Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/92.0.4515.131 Safari/537.36"
}
# 因为是post请求,所以必须要封装一个request对象(并携带参数)
req = urllib.request.Request(headers=headers, url=askUrl)
try:
response = urllib.request.urlopen(req) # 向服务器发送请求并获取响应
html = response.read().decode("gbk") # 对读取的内容进行格式编码(防止遇到中文出现乱码情况!)
except urllib.error.URLError as e: # 判断对象e是否存在code属性和reason属性,若有则输出!
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 初试化数据库(创建数据库and建表) 表名和数据库名不能相同!
def init_db(dbPath):
con = sqlite3.connect(dbPath) # 打开或创建数据库(建立连接)
cur = con.cursor() # 创建游标
# 用游标执行建表sql语句
cur.execute("""
create table jobInfo(
id integer primary key autoincrement, /* autoincrement:自增长 只有integer类型才能用!*/
job_href text,
job_name varchar,
company_href text,
company_name varchar,
providesalary_text text,
experience_info text,
degree varchar,
employee_num text,
workarea_text text,
updatedate text,
companytype_text text,
jobwelf text,
companysize_text text,
companyind_text text
);
""")
con.commit() # 提交数据库操作(事务提交,让此操作生效!)
cur.close() # 关闭游标
con.close() # 关闭连接
# 保存数据到sqlite数据库中
def saveDB(data_list, dbPath):
# init_db(dbPath) # 初始化数据库(建数据库+建表)
con = sqlite3.connect(dbPath) # 打开或创建数据库(建立连接)
cur = con.cursor() # 创建游标
# 用游标进行插入操作
# join()方法只能用于每一项都是字符串的列表!!!
for row in data_list: # 有多少行数据,就执行多少次输入语句
for index in range(len(row)): # 给每列元素添加一对双引号!
row[index]='"'+row[index]+'"'
sql = """
insert into jobInfo(job_href,job_name,company_href,company_name,providesalary_text,experience_info,degree,employee_num,workarea_text,updatedate,companytype_text,jobwelf,companysize_text,companyind_text)
values(%s)""" % (",".join(row))
# print(sql)
cur.execute(sql)
con.commit() # 提交数据库操作(事务提交,让此操作生效!)
cur.close() # 关闭游标
con.close() # 关闭连接
print("保存成功!")
# 测试建数据库和建表操作
# init_db(r"51job.db")
main()
print("爬取成功!请查看.db文件!")
以上代码是爬取51job搜搜大关键字数据的第11页-20页的数据!
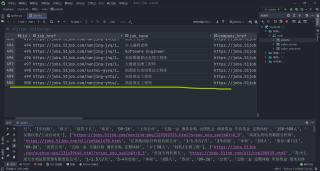
这里显示的500条是第一次操作存入表中数据,第二次的存入数据库操作怎么都搞不来!