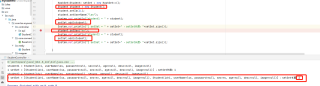
使用hashset存储两遍同一对象,但是再第二次存储之前,将该对象的一个属性值更改,然后往hashSet里存储,我以为会只有一条数据,但显示有两条数据。为什么会存进第二条数据?
另一个问题:
我选择打印地址不打印数据,打印出来的是我测试之前以为的一条记录。为什么打印具体数据和打印地址的结果不一样?
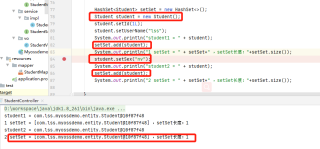
不同的只是Student类是否重写了toString():
求解答~

使用hashset存储两遍同一对象,但是再第二次存储之前,将该对象的一个属性值更改,然后往hashSet里存储,我以为会只有一条数据,但显示有两条数据。为什么会存进第二条数据?
另一个问题:
我选择打印地址不打印数据,打印出来的是我测试之前以为的一条记录。为什么打印具体数据和打印地址的结果不一样?
不同的只是Student类是否重写了toString():
求解答~
 分享
分享
回答你这个问题要从三个方向,让你彻底明白
HashSet的底层是什么?
这个不用想吧,是HashMap,如果不确定那就看一下源码!
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
Map 实现put的原则是什么?
Map 判断Key是否相同的逻辑是什么?
hash值吧,不确定我们就来看看源码
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
结合上面的分享我们就知道了,为何你修改了对象的属性,会存在两个对象了吧!究其原因是HashSet把你的实体类进行hash,实体类的值不一样了,hash值肯定不一样吧?
为什么你说输出的地址是一样的呢?那是因为你没有重写equals方法,那就直接用的是父类的equals方法,而父类的equals 方法是用==判断的,这就引出另一个问题 ==与equals的区别了
==:比较两个引用是不是指向同一个对象实例,即相同的地址。
equals:equals方法是Object类的方法,默认是直接调用==来实现。如果没有被重写,那么调用equals与==没有区别。
如果你想清晰的看清楚,就必须重写equals 与hashCode的方法,这两个放过也是判断对象是否相同的重要决定性因素!
也许你又会问,为什么我一个add方法,还需要和equals扯上关系,那么我们看看add方法的注释,如下
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
翻译:将指定的元素添加到此集合(如果尚未存在)。 更正式地,将指定的元素e添加到此集合,如果此集合不包含元素e2 ,使得(e==null ? e2==null : e.equals(e2)) 。 如果该集合已经包含该元素,则该呼叫将保持不变,并返回false 。
看完是不是恍然大悟了!希望被采纳!
分享 已结题
(查看结题原因) 10月14日
已采纳回答
10月12日
创建了问题
10月12日
已结题
(查看结题原因) 10月14日
已采纳回答
10月12日
创建了问题
10月12日




