
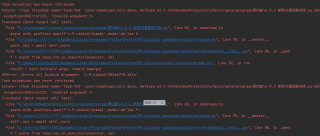
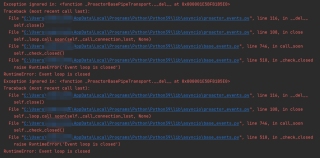
问题具体就是:在爬取一个网站的过程中,进程是已经爬取到了视频的m3u8文件;准备对文件里面的每一段m3u8文件链接进行下载,写完下载流程后开始报错,望指教?
问题截图:
'''
思路:
1、拿到主页面的页面源代码,找到iframe
2、从iframe页面源代码中拿到m3u8文件
3、下载第一层m3u8文件,拿到真实地址 ——>下载第二层真实的m3u8文件
4、下载视频
5、下载key(密钥),进行解密操作
6、合并所有ts文件为一个MP4文件
'''
import requests
from bs4 import BeautifulSoup #用来提取源代码里的数据
import re #使用正则提取源代码数据
import asyncio
import aiohttp #用来协程下载
import aiofiles #协程文件处理模块
#正则提取规则
obj1=re.compile(r'2.html","link_pre":"","url":"(?P<src>.*?)","url_next":"https:')
#2.1子程序:找到主页面的源代码,找到iframe对应的url
#在这一步课程91看剧里面,这里只是找到了iframe的url,需要进一步在这里提取第一层m3u8地址;但是在自己实操用的片吧网址,正则提取完之后就是第一层m3u8地址了
def get_iframe_src(url):
resp=requests.get(url)
#print(resp.text) #测试是否正常爬取到源代码
#修改为正则爬取,这里提取完之后就是第一层的m3u8地址了
content=resp.text #把源代码变成text格式存储起来,用来提取
main_page=obj1.finditer(content)
for it in main_page:
#print(it.group('src')) #这两行是为了查看是否正常读取到m3u8地址,并且去掉‘/’是否成功
src_modify=it.group('src').replace('\\','') #去掉链接中的反斜杠‘/’
#print(src_modify) #测试是否去除成功
return src_modify #输出正确的第一层m3u8地址
resp.close()
#2.2、子程序:拿到第一层的m3u8文件下载地址;这一步只在课程里91看剧需要,实操的网址2.1里拿到的就是第一层m3u8了
def get_first_m3u8_url(url):
resp=requests.get(url)
#print(resp.text)
obj2=re.compile(r'var main=''(?P<m3u8_url>.*?)''')
m3u8_url=obj2.search(resp.text).group('m3u8_url') #这里是把m3u8地址提取出来
#print(m3u8_url)
resp.close()
return m3u8_url #让函数返回这一个地址
#2.3、子程序:下载第一层m3u8文件
def download_m3u8_file(url,name):
resp=requests.get(url)
with open(name,mode='wb')as f:
f.write(resp.content)
resp.close()
#2.5.1、子程序:异步协程进行下载
async def download_ts(url,name,session):
async with session.get(url)as resp:
async with aiofiles.open(f'4.9-video2/{name}',mode='wb')as f:
await f.write(await resp.content.read()) #把下载到的内容写入文件中
print(f'{name}下载完毕')
#2.5、子程序:异步协程处理拼接下载
#实操版
async def aio_download(up_url):
tasks=[]
async with aiohttp.ClientSession() as session:
async with aiofiles.open('4.93-抓取91看剧复杂版——second-m3u8.txt',mode='r',encoding='utf-8')as f:
async for line in f:
if line.startswith('#'): #’#‘开头的行不要
continue
# line就是xxxx.ts文件
url = line.strip() # 去掉没用的空格和换行
name=line.rsplit('/',1)[1] #取网址最后一个斜杠后面的字符作为文件名,意思是:从右边切,切一次,得到【1】的位置的内容
task=asyncio.create_task(download_ts(url,name,session))
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
#2、主程序
def main(url):
#2.1、找到主页面的源代码,找到iframe对应的url
iframe_src=get_iframe_src(url)
#print(iframe_src)
#2.3下载第一层m3u8文件
download_m3u8_file(iframe_src,'4.93-抓取91看剧复杂版——first-m3u8.txt') #按照课程正常的话括号里的’iframe_src‘要改为2.2里的’first_m3u8_url_ture‘
#2.4下载第二层m3u8文件
# 比对一下两层m3u8
with open('4.93-抓取91看剧复杂版——first-m3u8.txt',mode='r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'): #让程序识别文件里面时,自动跳过‘#’开头的行段
continue
else:
line=line.strip() #去掉空白或者换行符
#准备拼接第二层m3u8的下载路径
second_m3u8_url=iframe_src.split('/20210730')[0]+line
download_m3u8_file(second_m3u8_url,'4.93-抓取91看剧复杂版——second-m3u8.txt')
print('第二层m3u8下载完毕')
#2.5下载视频
#实操写法
up_url='开始'
asyncio.run(aio_download(up_url))
#1、主程序调用处
if __name__=='__main__':
url='https://www.pianba.net/yun/84961-1-1/'
main(url)







