import requests
from lxml import etree
import pymysql
import re
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59',
}
url='https://www.gushiwen.cn/default_2.aspx'
def get_ancient_poetry():
response=requests.get(url,headers=headers)
content = response.content.decode('utf8')
html = etree.HTML(content)
titles=html.xpath('//div[@class="cont"]/p/a/b/text()') #古诗名
authors=html.xpath('//p[@class="source"]/a/text()') #作者
dynastys=html.xpath('//p[@class="source"]/a/text()') #朝代
content=html.xpath('//div[@class="contson"]/text()') #古诗内容
content=''.join(html.xpath('//div[@class="contson"]/text()')).strip()
pomes = []
print(content)
if __name__ == '__main__':
get_ancient_poetry()
这里我打印content返回是正常的古诗内容

import requests
from lxml import etree
import pymysql
import re
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59',
}
url='https://www.gushiwen.cn/default_2.aspx'
def get_ancient_poetry():
conn = pymysql.connect(host='localhost', user='root', password='123456', database='boss', port=3306)
cursor = conn.cursor()
response=requests.get(url,headers=headers)
content = response.content.decode('utf8')
html = etree.HTML(content)
titles=html.xpath('//div[@class="cont"]/p/a/b/text()') #古诗名
authors=html.xpath('//p[@class="source"]/a/text()') #作者
dynastys=html.xpath('//p[@class="source"]/a/text()') #朝代
content=html.xpath('//div[@class="contson"]/text()') #古诗内容
content=''.join(html.xpath('//div[@class="contson"]/text()')).strip()
pomes = []
for value in zip(titles, authors, dynastys, content):
title, author, dynasty, content = value
pome = {
'古诗名': title,
'作者': author,
'朝代': dynasty,
'古诗内容': content
}
pomes.append(pome)
for pome in pomes:
print(pome)
print('=' * 40)
if __name__ == '__main__':
get_ancient_poetry()
这样子写之后在打印发现古诗内容就获取了一个字这是为啥该怎么修改代码
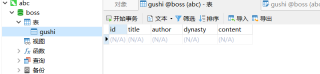
而且我还想保存到mysql数据库里面,表已经建好了但是不会能帮忙完善一下代码讲解一下吗