



3条回答 默认 最新
 CSDN专家-showbo 2021-10-28 15:35关注
CSDN专家-showbo 2021-10-28 15:35关注我这里跑没问题,题主代码出来看下,print(html)题主检查过有数据?有些时候反扒返回的也是html代码,但是不包含数据在里面的
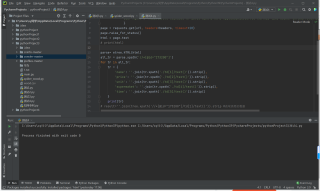
import csv #用于把爬取的数据存储为csv格式,可以excel直接打开的 import time #用于对请求加延时,爬取速度太快容易被反爬 from time import sleep #同上 import random #用于对延时设置随机数,尽量模拟人的行为 import requests #用于向网站发送请求 from lxml import etree #lxml为第三方网页解析库,强大且速度快 url = 'http://yz.yuzhuprice.com:8003/findPriceByName.jspx?page.curPage=1&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB' headers = { 'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36", } page = requests.get(url, headers=headers, timeout=10) page.raise_for_status() html = page.text parse = etree.HTML(html) #解析网页 all_tr = parse.xpath('//*[@id="173200"]') for tr in all_tr: tr = { 'name': ''.join(tr.xpath('./td[1]/text()')).strip(), 'price': ''.join(tr.xpath('./td[2]/text()')).strip(), 'unit': ''.join(tr.xpath('./td[3]/text()')).strip(), 'supermaket': ''.join(tr.xpath('./td[4]/text()')).strip(), 'time': ''.join(tr.xpath('./td[5]/text()')).strip() } print(tr)本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2021-10-28 14:19回答 3 已采纳 我这里跑没问题,题主代码出来看下,print(html)题主检查过有数据?有些时候反扒返回的也是html代码,但是不包含数据在里面的 import csv #用于把爬取的数据存储为csv格式,可
- 2024-01-06 11:58longfei815的博客 【代码】python爬虫,简单的requests的get请求,百度搜索实例。
- 2021-01-14 13:16weixin_39963096的博客 结 语 自此,红木数据爬虫代码写完啦,数据爬取下来后,就可以进行可视化的分析了,比如可以看下每年不同市场红木的价格走势,同一市场不同红木的价格走势,或者还可以建立起红木的价格指数。可视化的内容后续我会...
- 2021-01-30 00:03三木三土的博客 结 语 自此,红木数据爬虫代码写完啦,数据爬取下来后,就可以进行可视化的分析了,比如可以看下每年不同市场红木的价格走势,同一市场不同红木的价格走势,或者还可以建立起红木的价格指数。可视化的内容后续我会...
- 2023-05-25 17:24百事没事阿的博客 要知道互联网可不是法外之地,你一顿爬虫骚操作搞不好哪天就…首先,咱先看下爬虫的定义:网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取...
- 2023-05-03 21:41程序员源源的博客 要知道互联网可不是法外之地,你一顿爬虫骚操作搞不好哪天就…首先,咱先看下爬虫的定义:网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取...
- 2023-02-27 11:29Python编程开发的博客 本次爬虫小项目是应朋友需求,爬取中国木材价格指数网中的红木价格数据,方便撰写红木研究报告。网站长这样: 所需字段已用红框标记,数据量粗略看了下,1751页共5万多条记录,如果你妄想复制粘贴的话,都不知道粘到...
- 2023-09-21 21:15程序汪小陈的博客 要知道互联网可不是法外之地,你一顿爬虫骚操作搞不好哪天就…首先,咱先看下爬虫的定义:网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
11月5日
系统已结题
11月5日 已采纳回答
10月28日
已采纳回答
10月28日-
创建了问题
10月28日
悬赏问题
- ¥15 神经网络怎么把隐含层变量融合到损失函数中?
- ¥30 自适应 LMS 算法实现 FIR 最佳维纳滤波器matlab方案
- ¥15 lingo18勾选global solver求解使用的算法
- ¥15 全部备份安卓app数据包括密码,可以复制到另一手机上运行
- ¥15 Python3.5 相关代码写作
- ¥20 测距传感器数据手册i2c
- ¥15 RPA正常跑,cmd输入cookies跑不出来
- ¥15 求帮我调试一下freefem代码
- ¥15 matlab代码解决,怎么运行
- ¥15 R语言Rstudio突然无法启动