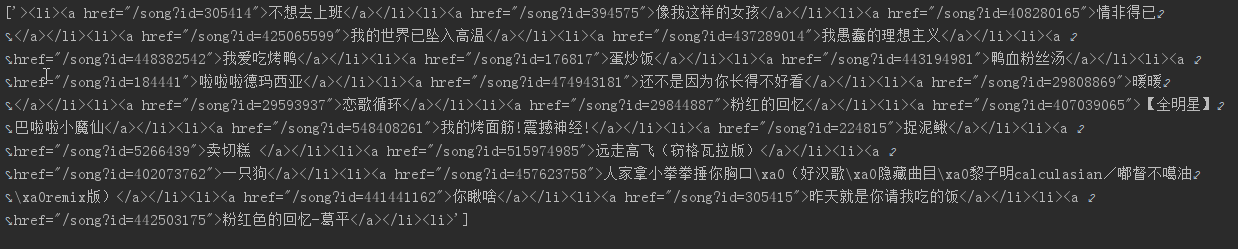
像是这段代码,如何通过正则表达式分别获取里面的歌名以及id=之后的数字
收起
re.findall('<li><a href="(.*?)">(.*?)</a></li>',searchstr,re.DOTALL)
报告相同问题?
程序员都在用的中文IT技术交流社区
专业的中文 IT 技术社区,与千万技术人共成长
关注【CSDN】视频号,行业资讯、技术分享精彩不断,直播好礼送不停!






 分享
分享






















