
- *
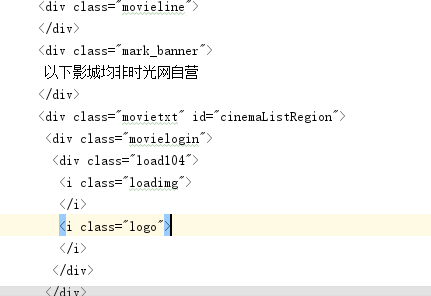
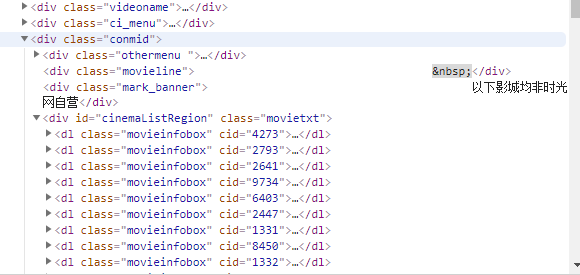
爬虫新手,爬取时光网热映电影想要爬取该电影的上映电影时间,价格,影院,但是不论是直接用request爬取还是PhantomJS爬取,都出现图片中问题,即load104,求大神帮帮忙
爬取网址:http://theater.mtime.com/China_Jiangsu_Province_Nanjing/movie/235701/
第一个图是我爬下来的内容
代码如下
import requests
import codecs
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate',
'accept-language': 'zh-CN,zh;q=0.9',
'referer': 'http://theater.mtime.com/China_Jiangsu_Province_Nanjing/',
'Host': 'theater.mtime.com',
}
def get_one_page(url,headers):
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def get_detail_onemovie(movid,date,headers):
url='http://theater.mtime.com/China_Jiangsu_Province_Nanjing/movie/'+movid+'/'+date+'/'
print(url)
html=get_one_page(url,headers)
soup = BeautifulSoup(html, 'lxml')
with codecs.open('one_page.txt', 'w', encoding='utf-8') as f:
f.write(soup.prettify())
get_detail_onemovie('235701','20190510',headers)
下面是模拟浏览器的代码
from selenium import webdriver
import codecs
driver = webdriver.PhantomJS()
driver.get('http://theater.mtime.com/China_Jiangsu_Province_Nanjing/movie/256175/20190509/')
with codecs.open('one_page.txt', 'w', encoding='utf-8') as f:
f.write(driver.page_source)
driver.close()





