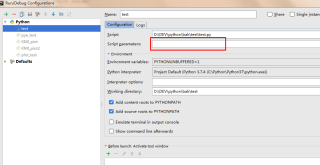
现有一段2008年的代码,其中的运行方法为
python %s [<文件名匹配式> [<更多文件名匹配式>...]]
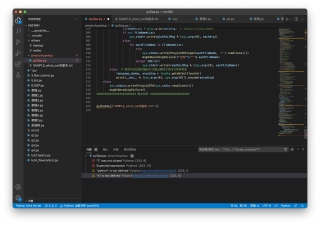
但是尝试在vscode上运行则会报错,如下图
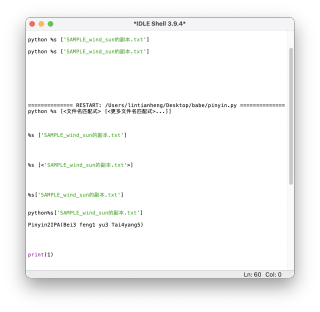
在新版IDLE上运行则无响应:
请问这个代码能如何被调用?谢谢!
附上完整代码:
# !/usr/bin/env python
# This file has following encoding: utf-8
######################## 模块文档 ########################
"""
“%s”汉语拼音-国际音标转换工具 2.1版(2007年9月16日)
作者:徐清白(http://xuqingbai.googlepages.com),首发于2007年8月6日
授权:自由软件(GNU 通用公共许可证)
要求:必须使用 Python 2.5 或更新版本的解释器运行
用法:python %s [<文件名匹配式> [<更多文件名匹配式>...]]
功能:从符合每个<文件名匹配式>的所有文件或标准输入流(stdin)读取汉语拼音文稿,
向标准输出流(stdout)写入经过转换得到国际音标文稿。结果仅供学习参考。
注意:<文件名匹配式> 采用 UNIX shell 风格的 glob 匹配规则
文稿格式:<单字拼音>[[ |']<更多单字拼音>...]
其中:<单字拼音> = <汉语拼音字母串>[<声调标号>]
<声调标号> 取值1-5(对应四声和轻声)
标音风格:适度严格的IPA音素音标+部分汉语言学界专用符号
详细的用户文档请参看“DOC_USERSGUIDE.html”文件
"""
######################## 模块导入 ########################
import os, re
######################## 全局变量 ########################
# 三种字符集标志
GB18030, GBK, UTF8 = "gb18030", "gbk", "utf8"
# 字符编码页解码失败标志
decodingFailed = False # 初始状态:关闭
# 正则表达式替换命令元组和内部标志
cmdPairTuple = tuple() # 预备空对象
PATTERN, SUBST = 0, 1 # 匹配段和替换段
# 经过编译的正则表达式对象列表
reList = [] # 预备空对象
# 创建正则表达式替换命令元组的默认设置表(固定集合对象)
defaultPrefSet = frozenset([
### 以下各行字符串,凡行首用#号注释者均表示无效;
### 凡行首未用#号注释者均有效,效用如后面注释所述:
# "NUMBER_2_BY_AR4", # 数字“二”有大开口度韵腹
# "AI_INC_NEAR_OPEN_FRONT", # ai/uai韵腹为舌面前次开元音
# "AIR_ANR_INC_NEAR_OPEN_CENTRAL", # air/anr韵腹为舌面央次低元音
# "CENTRAL_A_BY_SMALLCAPS_A", # “央a”采用小型大写[A]标明
# "IE_YUE_INC_SMALLCAPS_E", # ie/yue采用小型大写[E]标明
# "IE_YUE_INC_E", # ie/yue采用[e]标明(覆盖上一条)
# "IAN_YUAN_AS_AN", # ian/yuan韵腹和an一样
# "ONLY_YUAN_AS_AN", # 仅yuan韵腹和an一样(覆盖上一条)
# "OU_INC_SCHWA", # ou/iou采用舌面央中元音韵腹
# "IONG_BY_IUNG", # iong韵母采用i韵头u韵腹
# "ASPIRATE_BY_TURNED_COMMA", # 采用反逗号弱送气符号
# "RHOTICITY_BY_RHOTIC_HOOK", # 儿化韵卷舌动作采用卷舌小钩
# "ONLY_ER_BY_RHOTIC_HOOK", # 只有er音节卷舌动作采用卷舌小钩
# "INITIAL_R_BY_VED_RETRO_FRIC", # 声母r为卷舌浊擦音而非卷舌通音
# "R_TURNED_WITH_HOOK", # 严格采用卷舌通音符号
# "TRANSITIONAL_SCHWA_IN_ING", # ing有舌面央中元音韵腹
# "TRANSITIONAL_SCHWA_IN_UEN", # 合口un有舌面央中元音韵腹
# "NO_TRANSITIONAL_U", # bo/po/mo/fo没有[u]韵头
# "SYLLABLE_JUNCTURE_BY_PLUS", # 音节间断采用开音渡+号而非.号
# "HTML_SUP_TAG_FOR_TONE_VALUE", # 调值采用HTML上标标签格式
# "HIDE_ALL_TONE_VALUE", # 隐藏所有声调转换
### 以下选项仅存设想,目前尚未实现:
# "RETROFLEX_INITIAL_STANDALONE", # 卷舌声母可成音节而无需舌尖元音
# "ZERO_INITIAL_HAS_CONSONANT", # 零声母有辅音
])
# 正则表达式替换命令元组一揽子创建设置方案(元组,[0]位为说明)
recipeLinWang1992 = (U"林焘、王理嘉《语音学教程》",
"NO_TRANSITIONAL_U", "ASPIRATE_BY_TURNED_COMMA", "AI_INC_NEAR_OPEN_FRONT"
)
recipeBeidaCN2004 = (U"北京大学中文系《现代汉语》(重排本)",
"NO_TRANSITIONAL_U", "ASPIRATE_BY_TURNED_COMMA", "INITIAL_R_BY_VED_RETRO_FRIC",
"TRANSITIONAL_SCHWA_IN_UEN", "IONG_BY_IUNG", "IAN_YUAN_AS_AN"
)
recipeHuangLiao2002 = (U"黄伯荣、廖序东《现代汉语》(增订三版)",
"NO_TRANSITIONAL_U", "ASPIRATE_BY_TURNED_COMMA", "CENTRAL_A_BY_SMALLCAPS_A",
"TRANSITIONAL_SCHWA_IN_UEN", "ONLY_YUAN_AS_AN", "ONLY_ER_BY_RHOTIC_HOOK",
"INITIAL_R_BY_VED_RETRO_FRIC"
)
recipeYangZhou1995 = (U"杨润陆、周一民《现代汉语》(北师大文学院教材)",
"NO_TRANSITIONAL_U", "ASPIRATE_BY_TURNED_COMMA", "TRANSITIONAL_SCHWA_IN_UEN",
"INITIAL_R_BY_VED_RETRO_FRIC"
)
recipeYuan2001 = (U"袁家骅等《汉语方言概要》(第二版重排)",
"NO_TRANSITIONAL_U", "ASPIRATE_BY_TURNED_COMMA", "INITIAL_R_BY_VED_RETRO_FRIC",
"ONLY_ER_BY_RHOTIC_HOOK", "IAN_YUAN_AS_AN", "TRANSITIONAL_SCHWA_IN_UEN",
"IE_YUE_INC_E"
)
recipeTang2002 = (U"唐作藩《音韵学教程》(第三版)",
"NO_TRANSITIONAL_U", "ASPIRATE_BY_TURNED_COMMA", "INITIAL_R_BY_VED_RETRO_FRIC",
"ONLY_ER_BY_RHOTIC_HOOK", "IAN_YUAN_AS_AN", "TRANSITIONAL_SCHWA_IN_UEN",
"IE_YUE_INC_E", "OU_INC_SCHWA"
)
######################## 函数声明 ########################
def createCmdPairTuple(prefSet=defaultPrefSet):
"""创建正则表达式替换命令元组
然后编译便于反复使用的匹配段正则表达式对象列表
参数prefSet是一个控制命令元组创建的选项设置序列"""
### 预先处理同系列设置的覆盖关系——defaultPrefSet也可能让人动了手脚
prefSet = set(prefSet) # 先换为可变集合副本,以防固定类型参数
if "IE_YUE_INC_E" in prefSet and "IE_YUE_INC_SMALLCAPS_E" in prefSet:
prefSet.remove("IE_YUE_INC_SMALLCAPS_E")
if "ONLY_YUAN_AS_AN" in prefSet and "IAN_YUAN_AS_AN" in prefSet:
prefSet.remove("IAN_YUAN_AS_AN")
global cmdPairTuple
cmdPairTuple = (
### 转换声母前的预处理
# 音节间断与隔音符号
(R'([aoeiuvüê][1-5]?)([yw])', # a/o/e前有元音时必须写隔音符号
R"\1'\2"), # 标明不必写出隔音符号的音节间断
(R"'", (R"+" if "SYLLABLE_JUNCTURE_BY_PLUS" in prefSet else
R".")), # 音节间断(开音渡)标记
# 兼容正规的印刷体字母ɡ/ɑ->g/a
(R"ɡ", R"g"),
(R"ɑ", R"a"),
# 特殊的ê韵母,只能搭配零声母(“诶”字等)
(R"(ê|ea)", R"ɛ"), # ea是ê的GF 3006表示
# 消除因可以紧邻韵腹充当声母或韵尾的辅音的歧义
(R"r([aoeiu])", R"R\1"), # 声母r暂改为R,以免与卷舌标志r混淆
(R"n([aoeiuvü])", R"N\1"), # 声母n暂改为N,以免与韵尾n/ng混淆
# 需要排除式匹配转换的韵母
(R"ng(?![aeu])", R"ŋ"), # 双字母ng,后鼻音韵尾或自成音节
(R"(?<![ieuyüv])e(?![inŋr])",
R"ɤ"), # 单韵母e,此前已转换ea和声母r/n
(R"(?<![bpmfdtNlgkhjqxzcsRiywuüv])er4",
(R"ar4" if "NUMBER_2_BY_AR4" in prefSet else
R"er4")), # 数字“二”是否有大开口度韵腹
(R"(?<![bpmfdtNlgkhjqxzcsRiywuüv])ar4",
(R"a˞4" if "ONLY_ER_BY_RHOTIC_HOOK" in prefSet else
R"ar4")), # 数字“二”也属于er音节,可特别选用小钩
(R"a(?![ionŋ])", (R"ᴀ" if "CENTRAL_A_BY_SMALLCAPS_A" in prefSet else
R"a")), # “央a”是否用小型大写[A]标明,已转换“二”
(R"(?<![bpmfdtNlgkhjqxzcsRiywuüv])er",
(R"ə˞" if "ONLY_ER_BY_RHOTIC_HOOK" in prefSet else
R"ər")), # 一般的卷舌单韵母er,此前已排除“二”
(R"(?<![iuüv])er", R"ər"), # 构成单韵母e的儿化韵的er
(R"(?<=[bpmf])o(?![uŋ])",
(R"o" if "NO_TRANSITIONAL_U" in prefSet else
R"uo")), # bo/po/mo/fo是否有韵头u
### 声母——无需转换m/f/n/l/s/r(但r可根据设置执行转换)
# 送气清辅音声母
(R"([ptk])", R"\1ʰ"),
(R"q", R"tɕʰ"),
(R"(ch|ĉ)", R"tʂʰ"), # 后者是ch的注音变体
(R"c", R"tsʰ"), # 此前已排除ch
# 不送气清辅音声母
(R"b", R"p"), # 此前已排除送气的p/t/k
(R"d", R"t"),
(R"g", R"k"), # 此前已排除后鼻音双字母中的g,注意隔音
(R"j", R"tɕ"),
(R"(zh|ẑ)", R"tʂ"), # 后者是zh的注音变体
(R"z", R"ts"), # 此前已排除zh
# 擦音声母
(R"(sh|ŝ)", R"ʂ"), # 后者是sh的注音变体
(R"x", R"ɕ"), # 声母x,排除后再转换h
(R"h", R"x"), # 声母h,此前已排除zh/ch/sh
### 韵母
# 舌尖元音韵母
(R"(sʰ?)i", R"\1ɿ"), # zi/ci/si
(R"([ʂR]ʰ?)i", R"\1ʅ"), # zhi/chi/shi/ri
# 部分韵腹省略表示的韵母+隔音符号和韵头w/y
(R"iu", R"iou"), # 无需转换iou
(R"ui", R"uei"), # 无需转换uei
(R"wu?", R"u"),
(R"yi?", R"i"), # 此前已排除iu
# 韵头[i]/[y]的韵母
(R"iu|[üv]", R"y"), # 转换ü/v,恢复yu/yue,准备yuan/yun
(R"ian", (R"ian" if "IAN_YUAN_AS_AN" in prefSet else
R"iɛn")), # 是否认为ian韵腹和an一样
(R"yan", (R"yan" if ("ONLY_YUAN_AS_AN" in prefSet)
or ("IAN_YUAN_AS_AN" in prefSet) else
R"yɛn")), # 是否认为yuan韵腹和an一样(覆盖上一选项)
(R"(ɕʰ?)uan", (R"\1yan" if ("ONLY_YUAN_AS_AN" in prefSet)
or ("IAN_YUAN_AS_AN" in prefSet) else
R"\1yɛn")), # {j/q/x}uan,是否认为和an一样
(R"(ɕʰ?)u", R"\1y"), # {j/q/x}u{e/n}韵头,此前已排除{j/q/x}uan
(R"([iy])e(?!n)", (R"\1ᴇ" if "IE_YUE_INC_SMALLCAPS_E" in prefSet else
R"\1e")), # ie/yue/üe/ve,此前已转换{j/q/x}u
(R"([iy])e(?!n)", (R"\1e" if "IE_YUE_INC_E" in prefSet else
R"\1ɛ")), # ie/yue是否采用[e]标明,此前已判断[E]
# 舌面央中元音轻微过渡韵腹
(R"iŋ", (R"iəŋ" if "TRANSITIONAL_SCHWA_IN_ING" in prefSet else
R"iŋ")), # ing是否有舌面央中元音韵腹
(R"(un|uen)", (R"uən" if "TRANSITIONAL_SCHWA_IN_UEN" in prefSet else
R"un")), # 合口un/uen过渡,此前已排除撮口[j/q/x]un
# 后移的a
(R"ao", R"ɑu"), # 包括ao/iao,o改为u
(R"aŋ", R"ɑŋ"), # 包括ang/iang/uang
# 韵母en/eng韵腹是舌面央中元音
(R"e([nŋ])", R"ə\1"),
# ong类韵母
(R"ioŋ", (R"iuŋ" if "IONG_BY_IUNG" in prefSet else
R"yŋ")), # iong的两种转换,此前yong已转换为iong
(R"oŋ", R"uŋ"), # ong,此前已排除iong
### 儿化音变——无需转换ar/ir/ur/aur/our/yur
# 舌尖元音韵母
(R"[ɿʅ]r", R"ər"), # {zh/ch/sh/r/z/c/s}ir
# 鼻韵尾脱落和相应的韵腹元音替换
(R"[aɛ][in]r", (R"ɐr" if "AIR_ANR_INC_NEAR_OPEN_CENTRAL" in prefSet else
R"ar")), # air/anr韵尾脱落后的韵腹替换
(R"eir|ənr", R"ər"), # eir韵腹央化,韵尾脱落;enr韵尾脱落
(R"([iy])r", R"\1ər"), # ir/yr增加央化韵腹
(R"([iuy])nr", R"\1ər"), # inr/ynr/unr韵尾脱落后增加央化韵腹
(R"iuŋr", R"iũr"), # iungr(iongr的可选变换)
(R"([iuy])ŋr", R"\1ə̃r"), # ingr/yngr/ungr韵尾脱落后增加央化鼻化韵腹
(R"ŋr", R"̃r"), # ang/eng韵尾儿化脱落后韵腹鼻化
### 声母、韵母转换的善后扫尾工作
# 处理儿化韵卷舌动作
(R"r", (R"˞" if "RHOTICITY_BY_RHOTIC_HOOK" in prefSet else
R"r")), # 是否先把儿化韵卷舌动作改为卷舌小钩
(R"R", (R"ʐ" if "INITIAL_R_BY_VED_RETRO_FRIC" in prefSet else
R"r")), # 恢复声母r,是否采用卷舌浊擦音表示声母r
# 此前已处理完卷舌动作和声母,现在处理剩下的r字符的可选转换
(R"r", (R"ɻ" if "R_TURNED_WITH_HOOK" in prefSet else
R"r")), # 是否严格采用卷舌通音符号[ɻ]
# 恢复声母n
(R"N", R"n"), # 此前已处理完单元音韵母e和ie/yue
# 其他选项
(R"ʰ", (R"ʻ" if "ASPIRATE_BY_TURNED_COMMA" in prefSet else
R"ʰ")), # 是否采用反逗号送气符号
(R"ai", (R"æi" if "AI_INC_NEAR_OPEN_FRONT" in prefSet else
R"ai")), # (非儿化的)ai/uai韵腹为舌面前次开元音
(R"ou", (R"əu" if "OU_INC_SCHWA" in prefSet else
R"ou")), # ou/iou是否采用舌面央中元音韵腹
### 声调
# 先期处理
((R"[1-5]" if "HIDE_ALL_TONE_VALUE" in prefSet else
R"5"), R""), # 只隐藏轻声还是隐藏所有的声调转换
(R"([1-4])",
(R"<sup>\1</sup>" if "HTML_SUP_TAG_FOR_TONE_VALUE" in prefSet else
R"(\1)")), # 隔离单个数字调号
# 标出普通话调值
("([(>])1([)<])", R"\1 55\2"), # 阴平(第一声)
("([(>])2([)<])", R"\1 35\2"), # 阳平(第二声)
("([(>])3([)<])", R"\1 214\2"), # 上声(第三声)
("([(>])4([)<])", R"\1 51\2"), # 去声(第四声)
("([(>]) ([235])", R"\1\2") # 去掉此前标调值时加上的空格
)
### 以上,替换命令元组创建完成!
# 编译正则表达式对象,以便反复使用
global reList
reList = map(re.compile, [pair[PATTERN] for pair in cmdPairTuple])
def decodeLine(encodedLine):
"""对每一行拼音字符串做字符编码页解码"""
try:
decodedLine = encodedLine.decode(UTF8)
except UnicodeDecodeError: # 如果不是UTF-8
try:
decodedLine = encodedLine.decode(GB18030)
except UnicodeDecodeError: # 如果GB-18030也不行
decodedLine = "" + os.linesep # 解码失败,只能清空
global decodingFailed
decodingFailed = True # 设置字符编码页解码失败标志
except UnicodeEncodeError: # wx中可能出现编码错误
decodedLine = encodedLine
return decodedLine
def msgOnDecodingFailure(fileName="标准输入流"):
"""针对字符编码页解码失败的文件在事后通过标准错误流提出警告"""
global decodingFailed
if decodingFailed: # 检查上次文件处理中是否出现解码错误
sys.stderr.write((U"%s 警告:%s解码失败!" % (sys.argv[0], fileName)).encode(GBK) + os.linesep)
decodingFailed = False # 重置字符集码页解码失败标志为关闭
def convertLine(pinyinLine):
"""对每一行拼音字符串依次执行全部替换命令,像流编辑器sed一样工作"""
# 以单个“#”开头的行不转换,当作注释行
if pinyinLine.startswith("#") and not pinyinLine.startswith("##"):
return pinyinLine[1:] # 去掉开头的“#”后再返回
# 以两个“#”开头的行,只保留一个“#”,然后继续
if pinyinLine.startswith("##"):
pinyinLine = pinyinLine[1:]
ipaLine = pinyinLine.lower() # 大写字母在替换过程中另有意义
for eachRe, eachCmdPair in zip(reList, cmdPairTuple):
ipaLine = eachRe.sub(eachCmdPair[SUBST], ipaLine)
return ipaLine
def convertPinyin2IPA(pinyinLines, linesep=""):
"""将汉语拼音文稿转换为国际音标文稿
参数pinyinLines是输入的字符串序列
参数linesep是行分隔符(对于fp.readlines()或s.splitlines(True)的输入,缺省即可)"""
# 逐行处理解码和转换,有利于减少解码带来的乱码行
ipaLines = map(convertLine, map(decodeLine, pinyinLines))
return linesep.join(ipaLines).encode(UTF8) # 必须按UTF-8再encode一下
######################## 主干函数 ########################
def Pinyin2IPA(pinyinLines, *prefs):
"""创建转换命令,并将汉语拼音文稿转换为国际音标文稿
参数pinyinLines可以是字符串序列或单个字符串(后者也会包装进元组)
参数收集元组prefs是一个控制命令元组创建的选项设置表"""
# 根据设置表创建替换命令元组(设置表缺省时提供默认值)
if not prefs:
prefs = defaultPrefSet
createCmdPairTuple(prefs)
# 将单个字符串包装进元组,以便逐行处理
if isinstance(pinyinLines, str):
pinyinLines = (pinyinLines,)
return convertPinyin2IPA(pinyinLines)
######################## 直接运行 ########################
if __name__ == '__main__':
import glob, locale, sys
globFailMsg = U"%s 错误:参数“%s”不能匹配任何有效的文件名!"+ os.linesep
readFailMsg = U"%s 错误:文件“%s”数据读取失败!"+ os.linesep
if len(sys.argv) > 1:
if sys.argv[1].lower() not in ("/?", "/h", "--help", "-h"):
for eachArg in sys.argv[1:]: # 遍历glob表达式参数
fileNameList = glob.glob(eachArg) # 考虑DOS不负责glob解析
if not fileNameList:
sys.stderr.write(globFailMsg % (sys.argv[0], eachArg))
else:
for eachFileName in fileNameList:
try:
sys.stdout.write(Pinyin2IPA(open(eachFileName, 'r').readlines()))
msgOnDecodingFailure(U"文件“%s”" % eachFileName)
except IOError:
sys.stderr.write(readFailMsg % (sys.argv[0], eachFileName))
else: # 按照本地设置的编码方式输出模块文档作为简单帮助
language_dummy, encoding = locale.getdefaultlocale()
print(__doc__ % (sys.argv[0], sys.argv[0])).encode(encoding)
else:
sys.stdout.write(Pinyin2IPA(sys.stdin.readlines()))
msgOnDecodingFailure()
######################## 脚本结束 ########################