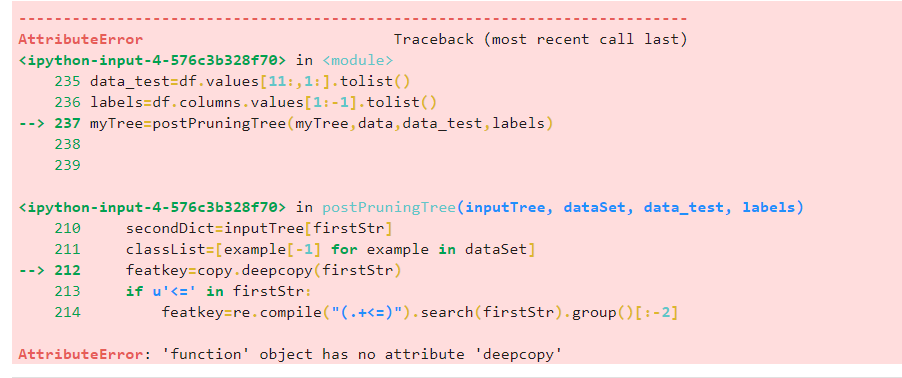
在进行决策树剪枝的时候出现AttributeError: 'function' object has no attribute 'deepcopy'错误,一直解决不了。

Python进行决策树剪枝提示AttributeError: 'function' object has no attribute 'deepcopy'。

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

3条回答 默认 最新

- 2020-07-26 15:30寻沂的博客 通过python实现简单的ID3决策树分裂算法
- 2020-07-13 03:44panfengblog的博客 决策树零基础入门到实践,理论部分:会介绍决策树的生成,决策树的各种种类(ID3、C4.5、CART)以及一些数据处理(缺失值和连续值)和优化(预剪枝和后剪枝)。实践部分:以Kaggle著名的Titanic数据集(点击这里)为...
- 2020-11-12 11:09满船清梦压星河HK的博客 plt.ylabel('target') #纵坐标叫标签 plt.title('Decision Tree Regression') #图的标题 plt.legend() #显示图例 plt.show() #显示 三、决策树实战-泰坦尼克号幸存者预测-sklearn import matplotlib.pyplot as plt ...
- 2019-02-21 15:55CoderBoom的博客 决策树剪枝:先剪枝(树生成之前或过程中进行剪枝)和后剪枝(树生长完成之后进行剪枝) 9.熵和信息熵详解 熵:物理学上,用于能量的分布的均匀性 信息熵:信息论上,用于消除信息的不确定性 信息熵:首先...
- 2025-11-27 19:24一阵劲爆的电吉他的博客 本文目标:用一份小型示例数据,演示如何构造决策树(ID3 风格,基于信息增益),使用(pre-pruning)和用验证集/测试集评估并对比效果。
- 2019-05-28 16:05时间_实践的博客 分类模型:决策树 目录 一、决策树的引入:................................................................................................................ 3 二、首先从一个实例讲起:........................
- 2015-04-16 22:31zbxzc的博客 CART(Classification And ...因此,CART算法生成的决策树是结构简洁的二叉树。如果目标变量是离散变量,则是classfication Tree,如果目标是连续变量,则是Regression Tree。CART树是二叉树,不像多叉树那样形成过多的
- 2025-05-05 16:11土城三富的博客 多叉树是一种每个节点最多有无限个子节点的树形数据结构。在多叉树中,节点的子节点数目没有固定的限制,与二叉树相比,它能够更好地模拟现实世界中的多种层级关系,比如组织结构图、多维索引等。多叉树的节点可以...
- 2023-07-20 01:28程序员光剑的博客 决策树(decision tree)是一个很古老但是应用非常广泛的机器学习模型。在数据挖掘、模式识别、图像处理等领域都有着广泛的应用。如何使用TensorFlow实现决策树呢?本文将从零开始,带领大家实现一个简单版本的决策...
- 2018-09-17 18:08无聊的六婆的博客 随机森林(Random Forest,RF)是Bagging的一个扩展变体,随机森林使用的基分类器是决策树,但是与传统的决策树不同的是,传统决策树在选择划分属性时在当前结点的属性集合中选择最优属性,而随机森林的决策树是先从该...
- 没有解决我的问题, 去提问
