
在调试的过程中,table 过滤语法更新,代码检查了没有问题。pandas已经更新到最新版本,1.34版本。
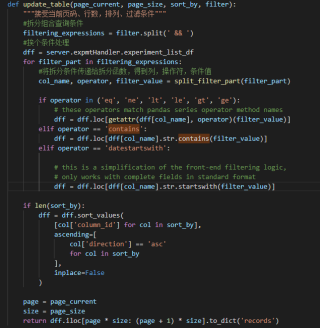
def update_table(page_current, page_size, sort_by, filter):
"""接受当前页码、行数,排列、过滤条件"""
#拆分组合查询条件
filtering_expressions = filter.split(' && ')
#挨个条件处理
dff = server.expmtHandler.experiment_list_df
for filter_part in filtering_expressions:
#将拆分条件传递给拆分函数,得到列,操作符,条件值
col_name, operator, filter_value = split_filter_part(filter_part)
if operator in ('eq', 'ne', 'lt', 'le', 'gt', 'ge'):
# these operators match pandas series operator method names
dff = dff.loc[getattr(dff[col_name], operator)(filter_value)]
elif operator == 'contains':
dff = dff.loc[dff[col_name].str.contains(filter_value)]
elif operator == 'datestartswith':
# this is a simplification of the front-end filtering logic,
# only works with complete fields in standard format
dff = dff.loc[dff[col_name].str.startswith(filter_value)]
if len(sort_by):
dff = dff.sort_values(
[col['column_id'] for col in sort_by],
ascending=[
col['direction'] == 'asc'
for col in sort_by
],
inplace=False
)
page = page_current
size = page_size
return dff.iloc[page * size: (page + 1) * size].to_dict('records')
# 条件拆分函数
def split_filter_part(filter_part):
operators = [['ge ', '>='],
['le ', '<='],
['lt ', '<'],
['gt ', '>'],
['ne ', '!='],
['eq ', '='],
['contains '],
['datestartswith ']]
# 循环自定义过滤类型
for operator_type in operators:
# 循环每个类型的两个元素
for operator in operator_type:
# 循环的元素(操作符)哎传入的过滤符号列表中
if operator in filter_part:
# 操作符分割传入的条件,只分割一次
name_part, value_part = filter_part.split(operator, 1)
# 取出大括号中的name
name = name_part[name_part.find('{') + 1: name_part.rfind('}')]
# 去掉空括号
value_part = value_part.strip()
# 特殊字符处理
v0 = value_part[0]
if (v0 == value_part[-1] and v0 in ("'", '"', '`')):
value = value_part[1: -1].replace('\\' + v0, v0)
else:
try:
value = float(value_part)
except ValueError:
value = value_part
# 在筛选字符串中,单词运算符后面需要空格,处理后就不需要啦
# word operators need spaces after them in the filter string,
# but we don't want these later
return name, operator_type[0].strip(), value
# 条件为空返回3个None
return [None] * 3
###### 运行结果及报错内容
```python
Traceback (most recent call last):
File "/Users/zhaoliu/Workspace/bee/app.py", line 96, in update_table
dff = dff[dff[col_name].str.contains(filter_value)]
File "/usr/local/anaconda3/envs/python37/lib/python3.7/site-packages/pandas/core/strings/accessor.py", line 101, in wrapper
return func(self, *args, **kwargs)
File "/usr/local/anaconda3/envs/python37/lib/python3.7/site-packages/pandas/core/strings/accessor.py", line 1111, in contains
result = self._array._str_contains(pat, case, flags, na, regex)
AttributeError: 'PandasArray' object has no attribute '_str_contains'
AttributeError: 'PandasArray' object has no attribute '_str_contains
File "/usr/local/anaconda3/envs/python37/lib/python3.7/site-packages/pandas/core/strings/accessor.py", line 101, in wrapper
msg = (
f"Cannot use .str.{func_name} with values of "
f"inferred dtype '{self._inferred_dtype}'."
)
raise TypeError(msg)
return func(self, *args, **kwargs)
wrapper.__name__ = func_name
return wrapper
return _forbid_nonstring_types
File "/usr/local/anaconda3/envs/python37/lib/python3.7/site-packages/pandas/core/strings/accessor.py", line 1111, in contains
result = self._array._str_contains(pat, case, flags, na, regex)
AttributeError: 'PandasArray' object has no attribute '_str_contains






