
###### 问题遇到的现象和发生背景
ef start_requests(self):
login_url = 'https://antispider7.scrape.center/api/login'
header = {
'Content-Type': 'application/json;charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
param = {
'password': 'admin',
'username': 'admin',
}
yield scrapy.Request(url=login_url, headers=header, body=json.dumps(param), method='POST', callback=self.login_callback)
def login_callback(self, response):
print(response.text)
jwt = 'jwt ' + json.loads(response.text)['token']
header = {
'Authorization': jwt
}
for page in range(1, 3):
url = 'https://antispider7.scrape.center/api/book/?limit=18&offset=%s' % ((page-1) * 18)
yield scrapy.Request(url=url, headers=header, callback=self.parse_list)
def parse_list(self, response):
print(response.text)
results = json.loads(response.text)
for result in results['results']:
book_id = result['id']
title = result['name']
score = result['score']
author = ''.join(result['author']).replace('\n', '').replace('\t', '').replace('\r', '')
outurl = result['cover']
print(book_id, title, score, author, outurl)
问题相关代码,请勿粘贴截图
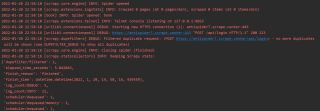
我需要先登录获取token加入到header中,因此我选择使用startr_requests来完成,但是yield之后始终没有任何回调函数捕捉到,请问可能的原因是什么?







