我用HtmlUnit中的WebClient.getPage()爬微博手机网页,但输出后发现比用浏览器查看的源码要少一部分标签,请教一下这是什么原因呢?有没有什么解决办法。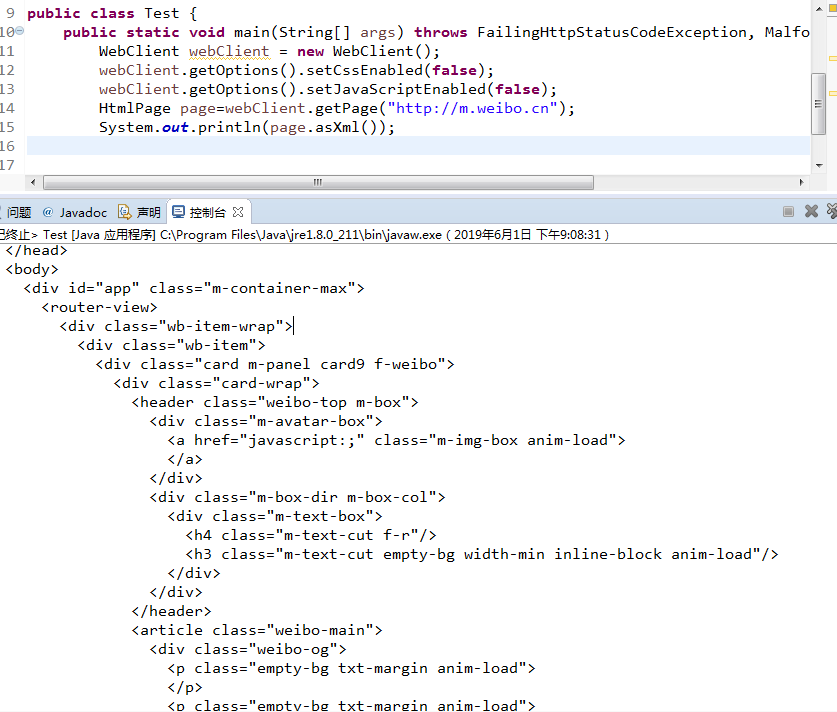
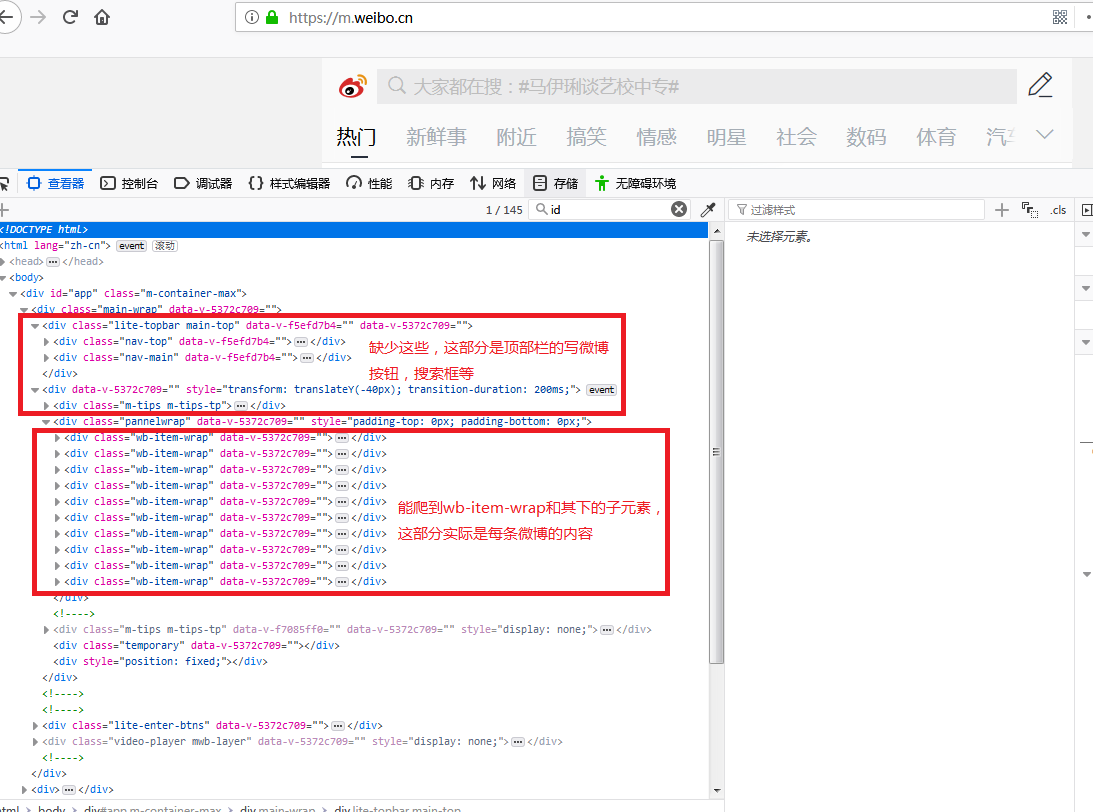

HtmlUnit爬网页不完整,缺少一些标签该如何解决?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

 关注
关注在使用HtmlUnit进行网页抓取时,遇到页面不完整或缺少标签的问题,通常是因为网页使用了大量的JavaScript进行动态内容加载。HtmlUnit对JavaScript的支持有限,可能无法完全模拟浏览器的行为。以下是解决方案:
启用JavaScript支持:
确保HtmlUnit的JavaScript支持是启用的,这可以通过设置WebClient来实现。WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false); // 可选
webClient.waitForBackgroundJavaScript(10000); // 设置等待时间
使用等待机制:
动态加载的内容需要一定的时间才能完全加载,可以设置等待时间来确保页面加载完成。webClient.waitForBackgroundJavaScriptStartingBefore(10000);
使用其他工具:
如果HtmlUnit不能满足需求,可以考虑使用Selenium,它能更好地处理JavaScript和动态内容。WebDriver driver = new ChromeDriver();
driver.get("http://example.com");
// 获取完整的页面源代码
String pageSource = driver.getPageSource();
通过以上方法,可以更好地抓取包含动态内容的网页。如果仍然遇到问题,可能需要结合其他工具或方法来处理复杂的JavaScript渲染。解决 无用评论 打赏举报 分享
- 2024-09-11 09:30境里婆娑的博客 通常在表达式求值或脚本执行过程中发生,常见原因包括语法错误、引用未定义的变量或方法、类型不匹配、空指针、脚本引擎错误以及资源缺失。为避免或处理,可以通过检查表达式语法、验证变量定义、处理类型转换、捕获...
- 2022-09-20 16:23xuhongxia&的博客 接口测试之HtmlUnit、OkHttp的简单了解
- 2020-09-19 15:38贰货不二的博客 尝试过Htmlunit和PhantomJS都无法抓取JS动态生成的页面,这两种方式实际抓取的都是原页面并不是js渲染之后的页面,后来经过尝试终于确定 Selenium + Chrome的方式能抓取js渲染之后的界面,其中也有不少坑,在这里...
- 2020-05-02 10:00眨眼睛1024的博客 需求:爬取项目中指定url页面,获取js执行后的html页面; 调整样式,将此html页面(需支持... 测试1:基于java嵌套浏览器:JBrowserDriver package test.mail.demo;...import java.io.File;...import java.io.IOExceptio...
- 2021-06-23 02:16胖五叔的博客 formId.submit()不能提交,就暂时只好把btnSubmit的type改为submit this.type="submit" 在网上查了资料,原因归结为两点: 1、表单中不能有name=”submit” 的标签 2、表单中不能缺少《enctype=”multipart/form-data...
- 2023-12-03 11:43_Aurora_&_&的博客 然而,传统的新闻网站和搜索引擎在新闻分类和检索方面存在一些限制。本项目的背景是开发一个新闻分类检索系统,利用爬虫技术从互联网上获取新闻文章,对其进行自动分类,然后提供用户友好的界面来实现高效的新闻检索...
- 2021-07-08 19:42TestCasees的博客 但由于现实项目中很多程序员其实写的代码并不规范,会缺少很多标准属性,这时就只有选择其他定位方法。 xpath很强悍,但定位性能不是很好,所以还是尽量少用。如果确实少数元素不好定位,可以选择xpath或cssSelector...
- 2016-12-13 10:43励志不回头的博客 如果你是爬虫开发老手,那么WebMagic会非常容易上手,它几乎使用Java原生的开发方式,只不过提供了一些模块化的约束,封装一些繁琐的操作,并且提供了一些便捷的功能。 如果你是爬虫开发新手,那么使用并了解...
- 2022-03-18 00:31React 中文社区的博客 Rhino,由 Mozilla 基金会管理,开放源代码,完全以 Java 编写,用于 HTMLUnit SpiderMonkey (Mozilla),第一款 JavaScript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。 Chakra (JScript 引擎)...
- 2021-03-24 08:34Yake1965的博客 因为它是一个指示浏览器做什么的进程外库,而且web平台本质上是异步的,所以WebDriver不跟踪DOM的实时活动状态。这伴随着一些我们将在这里讨论的挑战。 根据经验,大多数由于使用Selenium和WebDriver而产生的间歇性...
- 2020-09-03 17:22测试小小小的博客 Web自动化测试中的接口测试 ...服务器端的应用非常丰富,比如java的servlet,jsp,ssh框架,.net的aspx,还包括其他脚本如php,python。 web服务器端的设计架构近年来一直比较流行的是三层架构(3-tie.
- 2020-10-28 17:00奇舞周刊的博客 查看 d8 命令 # 如果不想使用./d8这种方式进行调试,可将d8加入环境变量,之后就可以直接`d8 --help`了 ./d8 --help 过滤特定的命令 # 如果是 Windows 系统,可能缺少 grep 程序,请自行下载安装并添加环境变量 ./...
- 2020-12-16 11:23小智大愚的博客 Rhino,由 Mozilla 基金会管理,开放源代码,完全以 Java 编写,用于 HTMLUnit SpiderMonkey (Mozilla),第一款 JavaScript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。 Chakra (JScript 引擎)...
- 2020-11-04 13:30程序员小乐的博客 Rhino,由 Mozilla 基金会管理,开放源代码,完全以 Java 编写,用于 HTMLUnit SpiderMonkey (Mozilla),第一款 JavaScript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。 Chakra (JScript 引擎)...
- 2019-10-04 03:09diaozhou2796的博客 maven下配置pom.xml 遇到的问题: 缺少依赖库。解决办法: 在build标签中添加: <plugin> <groupId>org.apache.maven.plugins</groupId&...
- 2018-12-26 14:44杏儿熟了的博客 HttpClient已经应用在很多的项目中,比如Apache Jakarta上很著名的另外两个开源项目Cactus和HTMLUnit都使用了HttpClient。 HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息...
- 没有解决我的问题, 去提问
