
你好,各位彦祖。
我导入了一个csv文件,第一列数据是取整数的序号从0-130,纵行名称为ac,但是每个序号有重复的对应了不同的数据,简略来说差不多如下图。
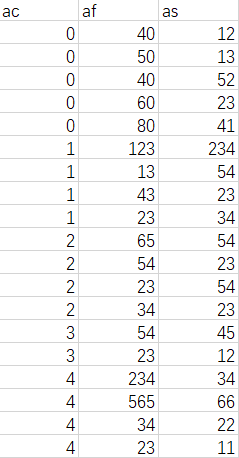
我尝试了用tidyverse里的group_by函数先对数据以ac为分组依据,然后用summarise函数以af为统计依据求每个组里的af最大值。
setwd("######")
DataOrigin<-read.csv("######.csv")
library(tidyverse)
data<-group_by(DataOrigin,ac)
summarise(data,afmax=max(af))
运行效果如图
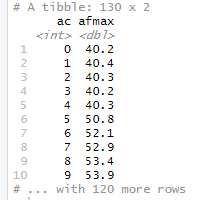
但是我还想要af取最大值时候对应那一行as的值
就是这样的效果
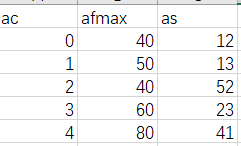
不知道该如何操作。
感激不尽!





