不知道为什么和网上up主输入的代码是一样的,但是最后爬取的网站页面代码和界面显示结果不一样。

为什么爬取的网站,页面代码少了好多,然后网站显示空白

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新
 CSDN专家-天际的海浪 2022-02-19 20:31关注
CSDN专家-天际的海浪 2022-02-19 20:31关注你是用requests爬取网页的吗
你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的内容取不到。
对于动态更新的内容要用selenium 来爬取。或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。
在页面上点击右键,右键菜单中选 "查看网页源代码"。
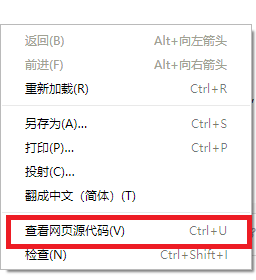
这样看到的才是网页的静态源代码。
如果这个网页的静态源代码中有你需要爬取的内容,就说明该页面没有动态内容,可以用requests爬取。
否则就说明该页面的内容是动态更新的,要用selenium 来爬取.
如果这个网页的静态源代码中有你需要爬取的内容,res.text中却没有,可能是requests伪造的头部信息不全。
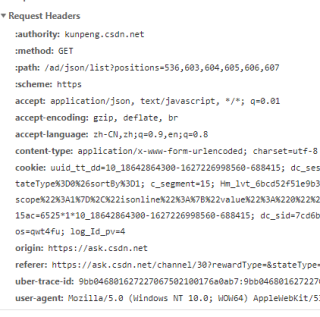
要在headers中添加抓包时的请求头求参数headers={ 'User-Agent': 'xxxxxxxxxxx', 'Host' : 'xxxxxxxxxxx', 'Origin' : 'xxxxxxxxxxxxx', 'Referer' : 'xxxxxxxxxxxxxx', 'Cookie': 'xxxxxxxxxxxxxxxx' }其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到
如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!
 本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 编辑记录 分享
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 编辑记录 分享
- 2021-08-08 11:16回答 2 已采纳 你只是爬取了html网页,,怎么能让你运行人家的网页呢你说的加载不出来那是肯定的这个样子应该你只是爬了个外壳,css和js都不能用了,所以背景是白的,按钮都是没有样式的如果明白了,点击右上角给个采纳哦
- 2022-03-05 11:56回答 1 已采纳 路径不要加中文呢
- 2022-04-07 11:17回答 3 已采纳 w改为a(追加),要不会将当前写入的内容覆盖文件内容 要么将open和close放到for循环外
- 2023-02-21 14:38例如,向金融界网站发送GET请求,获取指定日期的股票信息页面。代码可能如下: ```python import requests url = "http://stock.jrj.com.cn/tzzs/zdtwdj/zdforce.shtml" params = {"date": "2022-01-01"} # ...
- 2021-02-17 18:23回答 3 已采纳 在header参数中添加referer默认值,应该是直接访问触发反爬了
- 2021-05-28 19:50回答 3 已采纳 结合 selenium 库来操作。selenium 取到的 cookie 保存成文件,然后你这边 requests 请求的时候,去这个文件里读取最新的 token 值。
- 2021-10-21 15:16回答 1 已采纳 该页面信息通过用户选择选项,js动态渲染加载数据的,比如在选项框中输入name,在XHR中就可以看到name的动态加载链接,对其进行请求可获取相关信息的json数据信息。
- 2024-07-12 17:01.房东的猫的博客 定义: 深度优先搜索是一种遍历或搜索树或图的算法,从起始节点开始,一直沿着一个分支走到底,再回溯到上一个节点继续搜索下一个分支,...在大规模数据爬取时,选择合适的存储方式取决于数据的规模、结构和访问需求。
- 2021-04-22 11:19回答 4 已采纳 代码逻辑问题,main函数里只有计算耗时的部分,没有调用get_html、parse_html等函数。
- 2022-03-10 00:27回答 1 已采纳 这种结果用正则表达式提取就行,不能用xpath,另外如果结果数据类型为json的话可以把他转换成字典取值。python里面有json,jsonpath等模块就可以搞这种字符串的。有帮助的话采纳一下哦!
- 2022-07-06 12:00回答 4 已采纳 发我邮箱,email联系
- 2024-04-30 14:50m0_71441467的博客 假设response.text就是你显示的JSON格式的数据。# 打印状态码和响应文本,以便调试。
- 2020-12-22 19:08奇怪的同一个网站同一个榜单,只是页数不同,前若干页能爬取,后若干页就爬取不了,一度怀疑是不允许爬。 最后终于发现原因! 因为Cookie找错了(kao!!!!!) 注意要用这里的cookie! (下图是Chrome的开发者...
- 2021-02-10 18:23推广策划师阿宝的博客 来源:Mask 链接:...中途找到了几个页面发现不错,然后就开始思考怎么把页面给下载下来。由于之前还没有了解过爬虫,自然也就没有想到可以用爬虫来抓取网页内容。所以我采取的办法是:打开...
- 2020-08-24 13:44laoyouzhazi的博客 彼时深切体会到要想测试爬取“普通”反爬虫策略级别以上的网站内容,必须从浏览器内核级别入手。因为只有彻底模拟浏览器的行为,才无法被机器人100%识别为爬虫而遭到限制或拒绝服务。“爬虫”:与“反爬虫”是一对...
- 没有解决我的问题, 去提问



问题事件
 系统已结题
2月27日
系统已结题
2月27日 已采纳回答
2月19日
已采纳回答
2月19日-
创建了问题
2月19日
悬赏问题
- ¥30 Matlab打开默认名称带有/的光谱数据
- ¥50 easyExcel模板 动态单元格合并列
- ¥15 res.rows如何取值使用
- ¥15 在odoo17开发环境中,怎么实现库存管理系统,或独立模块设计与AGV小车对接?开发方面应如何设计和开发?请详细解释MES或WMS在与AGV小车对接时需完成的设计和开发
- ¥15 CSP算法实现EEG特征提取,哪一步错了?
- ¥15 游戏盾如何溯源服务器真实ip?需要30个字。后面的字是凑数的
- ¥15 vue3前端取消收藏的不会引用collectId
- ¥15 delphi7 HMAC_SHA256方式加密
- ¥15 关于#qt#的问题:我想实现qcustomplot完成坐标轴
- ¥15 下列c语言代码为何输出了多余的空格