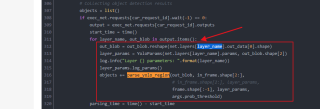
错误代码描述:
pi@raspberrypi:~ $ python3 SDK.py -m last.xml -i cam
[ INFO ] Creating Inference Engine...
[ INFO ] Loading network files:
last.xml
last.bin
SDK.py:218: DeprecationWarning: Reading network using constructor is deprecated. Please, use IECore.read_network() method instead
net = IENetwork(model=model_xml, weights=model_bin)
[ INFO ] Preparing inputs
[ INFO ] Loading model to the plugin
[ INFO ] Starting inference...
To close the application, press 'CTRL+C' here or switch to the output window and press ESC key
To switch between sync/async modes, press TAB key in the output window
(480, 640)
[ INFO ] Layer Transpose_258 parameters:
[ INFO ] classes : 63
[ INFO ] num : 3
[ INFO ] coords : 4
[ INFO ] anchors : [10.0, 13.0, 16.0, 30.0, 33.0, 23.0, 30.0, 61.0, 62.0, 45.0, 59.0, 119.0, 116.0, 90.0, 156.0, 198.0, 373.0, 326.0]
Traceback (most recent call last):
File "SDK.py", line 399, in <module>
sys.exit(main() or 0)
File "SDK.py", line 319, in main
args.prob_threshold)
File "SDK.py", line 146, in parse_yolo_region
out_blob_n, out_blob_c, out_blob_h, out_blob_w = blob.shape
ValueError: too many values to unpack (expected 4)
运行过程中,弹出摄像头窗口但没有图像,像是卡了一样,之后消失,伴随着终端提示上述错误,程序运行停止。
出错部分代码(完整代码位于问题描述后面)
def parse_yolo_region(blob, resized_image_shape, original_im_shape, params, threshold):
# ------------------------------------------ Validating output parameters ------------------------------------------
out_blob_n, out_blob_c, out_blob_h, out_blob_w = blob.shape #问题出现地!!!!!!!!!!!!!(我好苦恼)
predictions = 1.0 / (1.0 + np.exp(-blob))
assert out_blob_w == out_blob_h, "Invalid size of output blob. It sould be in NCHW layout and height should " \
"be equal to width. Current height = {}, current width = {}" \
"".format(out_blob_h, out_blob_w)
# ------------------------------------------ Extracting layer parameters -------------------------------------------
orig_im_h, orig_im_w = original_im_shape
resized_image_h, resized_image_w = resized_image_shape
objects = list()
side_square = params.side * params.side
# ------------------------------------------- Parsing YOLO Region output -------------------------------------------
bbox_size = int(out_blob_c / params.num) # 4+1+num_classes
for row, col, n in np.ndindex(params.side, params.side, params.num):
bbox = predictions[0, n * bbox_size:(n + 1) * bbox_size, row, col]
x, y, width, height, object_probability = bbox[:5]
class_probabilities = bbox[5:]
if object_probability < threshold:
continue
x = (2 * x - 0.5 + col) * (resized_image_w / out_blob_w)
y = (2 * y - 0.5 + row) * (resized_image_h / out_blob_h)
if int(resized_image_w / out_blob_w) == 8 & int(resized_image_h / out_blob_h) == 8: # 80x80,
idx = 0
elif int(resized_image_w / out_blob_w) == 16 & int(resized_image_h / out_blob_h) == 16: # 40x40
idx = 1
elif int(resized_image_w / out_blob_w) == 32 & int(resized_image_h / out_blob_h) == 32: # 20x20
idx = 2
width = (2 * width) ** 2 * params.anchors[idx * 6 + 2 * n]
height = (2 * height) ** 2 * params.anchors[idx * 6 + 2 * n + 1]
class_id = np.argmax(class_probabilities)
confidence = object_probability
objects.append(scale_bbox(x=x, y=y, height=height, width=width, class_id=class_id, confidence=confidence,
im_h=orig_im_h, im_w=orig_im_w, resized_im_h=resized_image_h,
resized_im_w=resized_image_w))
return objects
全部过程简介:YOLOv5迁移训练采用yolov5s.pt预训练模型,训练生成的.pt模型采用YOLOv5自带export.py文件转换成ONNX模型,转换之前更改了export.py中opset版本为10(附上export.py部分代码)
torch.onnx.export(model, im, f, verbose=False, opset_version=10,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['output'],
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
之后采用openVINO模型优化器中mo.py,将ONNX模型转换成 IR 格式文件。将树莓派搭建好openVINO,搭配openVINO官方YOLOv5推理程序与二代神经计算棒在树莓派上加速推理模型(出错)
附上完整openVINO官方提供推理程序
from __future__ import print_function, division
import logging
import os
import sys
from argparse import ArgumentParser, SUPPRESS
from math import exp as exp
from time import time
import numpy as np
import cv2
from openvino.inference_engine import IENetwork, IECore
logging.basicConfig(format="[ %(levelname)s ] %(message)s", level=logging.INFO, stream=sys.stdout)
log = logging.getLogger()
def build_argparser():
parser = ArgumentParser(add_help=False)
args = parser.add_argument_group('Options')
args.add_argument('-h', '--help', action='help', default=SUPPRESS, help='Show this help message and exit.')
args.add_argument("-m", "--model", help="Required. Path to an .xml file with a trained model.",
required=True, type=str)
args.add_argument("-i", "--input", help="Required. Path to an image/video file. (Specify 'cam' to work with "
"camera)", required=True, type=str)
args.add_argument("-l", "--cpu_extension",
help="Optional. Required for CPU custom layers. Absolute path to a shared library with "
"the kernels implementations.", type=str, default=None)
args.add_argument("-d", "--device",
help="Optional. Specify the target device to infer on; CPU, GPU, FPGA, HDDL or MYRIAD is"
" acceptable. The sample will look for a suitable plugin for device specified. "
"Default value is CPU", default="CPU", type=str)
args.add_argument("--labels", help="Optional. Labels mapping file", default=None, type=str)
args.add_argument("-t", "--prob_threshold", help="Optional. Probability threshold for detections filtering",
default=0.5, type=float)
args.add_argument("-iout", "--iou_threshold", help="Optional. Intersection over union threshold for overlapping "
"detections filtering", default=0.4, type=float)
args.add_argument("-ni", "--number_iter", help="Optional. Number of inference iterations", default=1, type=int)
args.add_argument("-pc", "--perf_counts", help="Optional. Report performance counters", default=False,
action="store_true")
args.add_argument("-r", "--raw_output_message", help="Optional. Output inference results raw values showing",
default=False, action="store_true")
args.add_argument("--no_show", help="Optional. Don't show output", action='store_true')
return parser
class YoloParams:
# ------------------------------------------- Extracting layer parameters ------------------------------------------
# Magic numbers are copied from yolo samples
def __init__(self, param, side):
self.num = 3 if 'num' not in param else int(param['num'])
self.coords = 4 if 'coords' not in param else int(param['coords'])
self.classes = 80 if 'classes' not in param else int(param['classes'])
self.side = side
self.anchors = [10.0, 13.0, 16.0, 30.0, 33.0, 23.0, 30.0, 61.0, 62.0, 45.0, 59.0, 119.0, 116.0, 90.0, 156.0,
198.0,
373.0, 326.0] if 'anchors' not in param else [float(a) for a in param['anchors'].split(',')]
self.isYoloV3 = False
if param.get('mask'):
mask = [int(idx) for idx in param['mask'].split(',')]
self.num = len(mask)
maskedAnchors = []
for idx in mask:
maskedAnchors += [self.anchors[idx * 2], self.anchors[idx * 2 + 1]]
self.anchors = maskedAnchors
self.isYoloV3 = True # Weak way to determine but the only one.
def log_params(self):
params_to_print = {'classes': self.classes, 'num': self.num, 'coords': self.coords, 'anchors': self.anchors}
[log.info(" {:8}: {}".format(param_name, param)) for param_name, param in params_to_print.items()]
def letterbox(img, size=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True):
# Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232
shape = img.shape[:2] # current shape [height, width]
w, h = size
# Scale ratio (new / old)
r = min(h / shape[0], w / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = w - new_unpad[0], h - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, 64), np.mod(dh, 64) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (w, h)
ratio = w / shape[1], h / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
top2, bottom2, left2, right2 = 0, 0, 0, 0
if img.shape[0] != h:
top2 = (h - img.shape[0]) // 2
bottom2 = top2
img = cv2.copyMakeBorder(img, top2, bottom2, left2, right2, cv2.BORDER_CONSTANT, value=color) # add border
elif img.shape[1] != w:
left2 = (w - img.shape[1]) // 2
right2 = left2
img = cv2.copyMakeBorder(img, top2, bottom2, left2, right2, cv2.BORDER_CONSTANT, value=color) # add border
return img
def scale_bbox(x, y, height, width, class_id, confidence, im_h, im_w, resized_im_h=640, resized_im_w=640):
gain = min(resized_im_w / im_w, resized_im_h / im_h) # gain = old / new
pad = (resized_im_w - im_w * gain) / 2, (resized_im_h - im_h * gain) / 2 # wh padding
x = int((x - pad[0]) / gain)
y = int((y - pad[1]) / gain)
w = int(width / gain)
h = int(height / gain)
xmin = max(0, int(x - w / 2))
ymin = max(0, int(y - h / 2))
xmax = min(im_w, int(xmin + w))
ymax = min(im_h, int(ymin + h))
# Method item() used here to convert NumPy types to native types for compatibility with functions, which don't
# support Numpy types (e.g., cv2.rectangle doesn't support int64 in color parameter)
return dict(xmin=xmin, xmax=xmax, ymin=ymin, ymax=ymax, class_id=class_id.item(), confidence=confidence.item())
def entry_index(side, coord, classes, location, entry):
side_power_2 = side ** 2
n = location // side_power_2
loc = location % side_power_2
return int(side_power_2 * (n * (coord + classes + 1) + entry) + loc)
def parse_yolo_region(blob, resized_image_shape, original_im_shape, params, threshold):
# ------------------------------------------ Validating output parameters ------------------------------------------
out_blob_n, out_blob_c, out_blob_h, out_blob_w = blob.shape
predictions = 1.0 / (1.0 + np.exp(-blob))
assert out_blob_w == out_blob_h, "Invalid size of output blob. It sould be in NCHW layout and height should " \
"be equal to width. Current height = {}, current width = {}" \
"".format(out_blob_h, out_blob_w)
# ------------------------------------------ Extracting layer parameters -------------------------------------------
orig_im_h, orig_im_w = original_im_shape
resized_image_h, resized_image_w = resized_image_shape
objects = list()
side_square = params.side * params.side
# ------------------------------------------- Parsing YOLO Region output -------------------------------------------
bbox_size = int(out_blob_c / params.num) # 4+1+num_classes
for row, col, n in np.ndindex(params.side, params.side, params.num):
bbox = predictions[0, n * bbox_size:(n + 1) * bbox_size, row, col]
x, y, width, height, object_probability = bbox[:5]
class_probabilities = bbox[5:]
if object_probability < threshold:
continue
x = (2 * x - 0.5 + col) * (resized_image_w / out_blob_w)
y = (2 * y - 0.5 + row) * (resized_image_h / out_blob_h)
if int(resized_image_w / out_blob_w) == 8 & int(resized_image_h / out_blob_h) == 8: # 80x80,
idx = 0
elif int(resized_image_w / out_blob_w) == 16 & int(resized_image_h / out_blob_h) == 16: # 40x40
idx = 1
elif int(resized_image_w / out_blob_w) == 32 & int(resized_image_h / out_blob_h) == 32: # 20x20
idx = 2
width = (2 * width) ** 2 * params.anchors[idx * 6 + 2 * n]
height = (2 * height) ** 2 * params.anchors[idx * 6 + 2 * n + 1]
class_id = np.argmax(class_probabilities)
confidence = object_probability
objects.append(scale_bbox(x=x, y=y, height=height, width=width, class_id=class_id, confidence=confidence,
im_h=orig_im_h, im_w=orig_im_w, resized_im_h=resized_image_h,
resized_im_w=resized_image_w))
return objects
def intersection_over_union(box_1, box_2):
width_of_overlap_area = min(box_1['xmax'], box_2['xmax']) - max(box_1['xmin'], box_2['xmin'])
height_of_overlap_area = min(box_1['ymax'], box_2['ymax']) - max(box_1['ymin'], box_2['ymin'])
if width_of_overlap_area < 0 or height_of_overlap_area < 0:
area_of_overlap = 0
else:
area_of_overlap = width_of_overlap_area * height_of_overlap_area
box_1_area = (box_1['ymax'] - box_1['ymin']) * (box_1['xmax'] - box_1['xmin'])
box_2_area = (box_2['ymax'] - box_2['ymin']) * (box_2['xmax'] - box_2['xmin'])
area_of_union = box_1_area + box_2_area - area_of_overlap
if area_of_union == 0:
return 0
return area_of_overlap / area_of_union
def main():
args = build_argparser().parse_args()
model_xml = args.model
model_bin = os.path.splitext(model_xml)[0] + ".bin"
# ------------- 1. Plugin initialization for specified device and load extensions library if specified -------------
log.info("Creating Inference Engine...")
ie = IECore()
if args.cpu_extension and 'CPU' in args.device:
ie.add_extension(args.cpu_extension, "CPU")
# -------------------- 2. Reading the IR generated by the Model Optimizer (.xml and .bin files) --------------------
log.info("Loading network files:\n\t{}\n\t{}".format(model_xml, model_bin))
net = IENetwork(model=model_xml, weights=model_bin)
# ---------------------------------- 3. Load CPU extension for support specific layer ------------------------------
if "CPU" in args.device:
supported_layers = ie.query_network(net, "CPU")
not_supported_layers = [l for l in net.layers.keys() if l not in supported_layers]
if len(not_supported_layers) != 0:
log.error("Following layers are not supported by the plugin for specified device {}:\n {}".
format(args.device, ', '.join(not_supported_layers)))
log.error("Please try to specify cpu extensions library path in sample's command line parameters using -l "
"or --cpu_extension command line argument")
sys.exit(1)
assert len(net.inputs.keys()) == 1, "Sample supports only YOLO V3 based single input topologies"
# ---------------------------------------------- 4. Preparing inputs -----------------------------------------------
log.info("Preparing inputs")
input_blob = next(iter(net.inputs))
# Defaulf batch_size is 1
net.batch_size = 1
# Read and pre-process input images
n, c, h, w = net.inputs[input_blob].shape
if args.labels:
with open(args.labels, 'r') as f:
labels_map = [x.strip() for x in f]
else:
labels_map = None
input_stream = 0 if args.input == "cam" else args.input
is_async_mode = True
cap = cv2.VideoCapture(input_stream)
number_input_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
number_input_frames = 1 if number_input_frames != -1 and number_input_frames < 0 else number_input_frames
wait_key_code = 1
# Number of frames in picture is 1 and this will be read in cycle. Sync mode is default value for this case
if number_input_frames != 1:
ret, frame = cap.read()
else:
is_async_mode = False
wait_key_code = 0
# ----------------------------------------- 5. Loading model to the plugin -----------------------------------------
log.info("Loading model to the plugin")
exec_net = ie.load_network(network=net, num_requests=2, device_name=args.device)
cur_request_id = 0
next_request_id = 1
render_time = 0
parsing_time = 0
# ----------------------------------------------- 6. Doing inference -----------------------------------------------
log.info("Starting inference...")
print("To close the application, press 'CTRL+C' here or switch to the output window and press ESC key")
print("To switch between sync/async modes, press TAB key in the output window")
while cap.isOpened():
# Here is the first asynchronous point: in the Async mode, we capture frame to populate the NEXT infer request
# in the regular mode, we capture frame to the CURRENT infer request
if is_async_mode:
ret, next_frame = cap.read()
else:
ret, frame = cap.read()
if not ret:
break
if is_async_mode:
request_id = next_request_id
in_frame = letterbox(frame, (w, h))
else:
request_id = cur_request_id
in_frame = letterbox(frame, (w, h))
in_frame0 = in_frame
# resize input_frame to network size
in_frame = in_frame.transpose((2, 0, 1)) # Change data layout from HWC to CHW
in_frame = in_frame.reshape((n, c, h, w))
# Start inference
start_time = time()
exec_net.start_async(request_id=request_id, inputs={input_blob: in_frame})
det_time = time() - start_time
# Collecting object detection results
objects = list()
if exec_net.requests[cur_request_id].wait(-1) == 0:
output = exec_net.requests[cur_request_id].outputs
start_time = time()
for layer_name, out_blob in output.items():
out_blob = out_blob.reshape(net.layers[layer_name].out_data[0].shape)
layer_params = YoloParams(net.layers[layer_name].params, out_blob.shape[2])
log.info("Layer {} parameters: ".format(layer_name))
layer_params.log_params()
objects += parse_yolo_region(out_blob, in_frame.shape[2:],
# in_frame.shape[2:], layer_params,
frame.shape[:-1], layer_params,
args.prob_threshold)
parsing_time = time() - start_time
# Filtering overlapping boxes with respect to the --iou_threshold CLI parameter
objects = sorted(objects, key=lambda obj: obj['confidence'], reverse=True)
for i in range(len(objects)):
if objects[i]['confidence'] == 0:
continue
for j in range(i + 1, len(objects)):
if intersection_over_union(objects[i], objects[j]) > args.iou_threshold:
objects[j]['confidence'] = 0
# Drawing objects with respect to the --prob_threshold CLI parameter
objects = [obj for obj in objects if obj['confidence'] >= args.prob_threshold]
if len(objects) and args.raw_output_message:
log.info("\nDetected boxes for batch {}:".format(1))
log.info(" Class ID | Confidence | XMIN | YMIN | XMAX | YMAX | COLOR ")
origin_im_size = frame.shape[:-1]
print(origin_im_size)
for obj in objects:
# Validation bbox of detected object
if obj['xmax'] > origin_im_size[1] or obj['ymax'] > origin_im_size[0] or obj['xmin'] < 0 or obj['ymin'] < 0:
continue
color = (int(min(obj['class_id'] * 12.5, 255)),
min(obj['class_id'] * 7, 255), min(obj['class_id'] * 5, 255))
det_label = labels_map[obj['class_id']] if labels_map and len(labels_map) >= obj['class_id'] else \
str(obj['class_id'])
if args.raw_output_message:
log.info(
"{:^9} | {:10f} | {:4} | {:4} | {:4} | {:4} | {} ".format(det_label, obj['confidence'], obj['xmin'],
obj['ymin'], obj['xmax'], obj['ymax'],
color))
cv2.rectangle(frame, (obj['xmin'], obj['ymin']), (obj['xmax'], obj['ymax']), color, 2)
cv2.putText(frame,
"#" + det_label + ' ' + str(round(obj['confidence'] * 100, 1)) + ' %',
(obj['xmin'], obj['ymin'] - 7), cv2.FONT_HERSHEY_COMPLEX, 0.6, color, 1)
# Draw performance stats over frame
inf_time_message = "Inference time: N\A for async mode" if is_async_mode else \
"Inference time: {:.3f} ms".format(det_time * 1e3)
render_time_message = "OpenCV rendering time: {:.3f} ms".format(render_time * 1e3)
async_mode_message = "Async mode is on. Processing request {}".format(cur_request_id) if is_async_mode else \
"Async mode is off. Processing request {}".format(cur_request_id)
parsing_message = "YOLO parsing time is {:.3f} ms".format(parsing_time * 1e3)
cv2.putText(frame, inf_time_message, (15, 15), cv2.FONT_HERSHEY_COMPLEX, 0.5, (200, 10, 10), 1)
cv2.putText(frame, render_time_message, (15, 45), cv2.FONT_HERSHEY_COMPLEX, 0.5, (10, 10, 200), 1)
cv2.putText(frame, async_mode_message, (10, int(origin_im_size[0] - 20)), cv2.FONT_HERSHEY_COMPLEX, 0.5,
(10, 10, 200), 1)
cv2.putText(frame, parsing_message, (15, 30), cv2.FONT_HERSHEY_COMPLEX, 0.5, (10, 10, 200), 1)
start_time = time()
if not args.no_show:
cv2.imshow("DetectionResults", frame)
render_time = time() - start_time
if is_async_mode:
cur_request_id, next_request_id = next_request_id, cur_request_id
frame = next_frame
if not args.no_show:
key = cv2.waitKey(wait_key_code)
# ESC key
if key == 27:
break
# Tab key
if key == 9:
exec_net.requests[cur_request_id].wait()
is_async_mode = not is_async_mode
log.info("Switched to {} mode".format("async" if is_async_mode else "sync"))
cv2.destroyAllWindows()
if __name__ == '__main__':
sys.exit(main() or 0)