
想要筛选多列中包含某一字符的行,
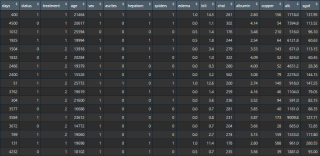
如图,如果想要筛选出hepatom/spiders/edema/bili/chol的任意一列中包含1的行,并输出成一个新表,需要怎么办啊?
这个图中列数很少,所以能通过类似枚举的方法完成。但是实际情况有几百列,通过枚举太耗时间了,能不能利用循环完成筛选呢?

想要筛选多列中包含某一字符的行,
 分享
分享
用循环来做的话,可以参考如下代码:
df<-read.csv('t0310.csv')
col=colnames(df)[2:5]
res=data.frame()
for (x in col){
d<-df[which(df[x]==1),]
res<-rbind(res,d)
}
res<-res[!duplicated(res$a),]
print(res)
 系统已结题
3月19日
系统已结题
3月19日 已采纳回答
3月11日
创建了问题
3月9日
已采纳回答
3月11日
创建了问题
3月9日


