25.追龙Ⅱ
小白询问如何爬取追龙谢谢
收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
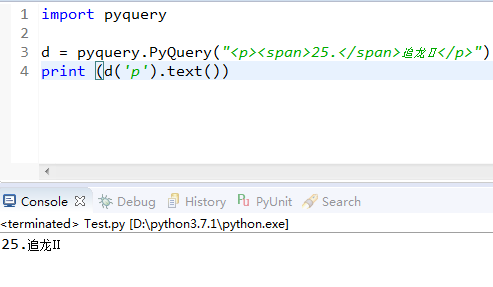
PyQuery: 一个类似jQuery的Python库
import pyquery d = pyquery.PyQuery("<p><span>25.</span>追龙Ⅱ</p>") #可以直接拼HTML print (d('p').text())
报告相同问题?

 分享
分享
 分享
分享




