
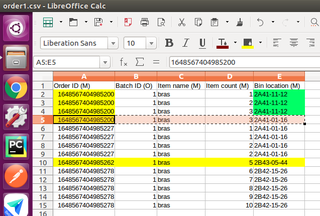
如上图所示订单csv中,第一列为订单号,第四列为数量,第五列为商品货位,相同货位是相同商品.
如果一行中第一列和第五列相同,则将他们第四列的数量相加,变成一行
如果一行中,第一列相同,第五列不同,则不相加,保持原样
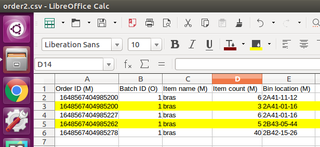
处理后生成新的csv变成下图的样子
感谢指教和帮忙
Order ID (M),Batch ID (O),Item name (M),Item count (M),Bin location (M)
1648567404985200,1,bras,1,2A41-11-12
1648567404985200,1,bras,2,2A41-11-12
1648567404985200,1,bras,3,2A41-11-12
1648567404985227,1,bras,1,2A41-01-16
1648567404985227,1,bras,1,2A41-01-16
1648567404985227,1,bras,2,2A41-01-16
1648567404985227,1,bras,2,2A41-01-16
1648567404985262,1,bras,5,2B43-05-44
1648567404985278,1,bras,6,2B42-15-26
1648567404985278,1,bras,7,2B42-15-26
1648567404985278,1,bras,8,2B42-15-26
1648567404985278,1,bras,9,2B42-15-26
1648567404985278,1,bras,10,2B42-15-26







