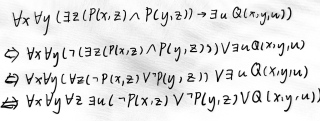关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
s-Prime
2022-04-23 14:53
采纳率: 100%
浏览 162
首页
吐槽问答
已结题
关于离散数学前束范式的问题
¥10
问答团队
离散数学求前束范式,问题点,p的式子和q的式子都有x和y所以换名规则不好用,,也不能直接把存在符号拿出了。所以想了好久还是不会做。难道是要把任意拿进去吗,请提供相关思路和解释,谢谢!一定采纳!
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
3
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
千鱼干
2022-04-23 22:45
关注
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
1
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
编辑记录
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(2条)
向“C知道”追问
报告相同问题?
提交
关注问题
朱松纯:三读《赤壁赋》,从人工智能的角度解读“心”与“理”的平衡
2022-01-08 22:00
Datawhale的博客
人们在能级跳跃(特别是向下)过程中,往往有感而发,也能发出五颜六色的“光”,这包括互联网上的
吐槽
、流行歌曲和带有审美的诗辞歌赋。本文要讨论的《赤壁赋》就是苏轼在人生大变局、能级大跳跃(从高向低)的时刻...
51c自动驾驶~合集63
2025-12-23 22:37
whaosoft-143的博客
所以三端统一 Trigger 的目标非常朴素: 关于“什么算一次事件 / 什么算一个
问题
”的逻辑,只写一份 Trigger 代码, 云端 / 车端 / 仿真三端都用这一份。 四、Trigger 框架总体设计:一套 Python,三端 Runtime 在...
文本已死,视觉当立!Karpathy狂赞DeepSeek新模型,终结分词器时代
2025-10-22 09:31
通俗易懂学IT的博客
“分词器就像给AI戴了副度数不准的眼镜,”Karpathy在之前的演讲里
吐槽
,“我们花了十年优化词表,却始终解决不了‘看到的字不是字’的根本
问题
。”据统计,传统大模型30%的推理错误都源于分词偏差,而处理小语种时...
51c大模型~合集179
2025-09-07 00:16
whaosoft-143的博客
然而,在更具挑战性的评估和实际使用中,准确度会固定在 100% 以下,因为有些
问题
的答案由于各种原因(例如信息不可用、小型模型的思维能力有限或需要澄清的歧义)而无法确定。OpenAI 举了个例子,当向不同的广泛...
51c大模型~合集157
2025-07-21 19:59
whaosoft-143的博客
通过将图像与文本深度融合,LVLMs 在图文
问答
、视觉推理等任务中大放异彩。但与此同时,一个严峻的
问题
也悄然浮现 ——LVLMs 比起纯文本模型更容易被 “越狱”。攻击者仅需通过图像注入危险意图,即使搭配直白的指令...
51c大模型~合集160
2025-07-27 19:19
whaosoft-143的博客
更令人惊喜的是,环节结束时,检测到电量亏损的灵犀 X2 突然 “
吐槽
”:“下次对话前,可以先让我充个电吗?深度对话还挺耗电的。” 引发现场一片掌声和欢笑,生动展现了人机交互的温度与活力。 这场对话不仅是技术...
51c大模型~合集131
2025-05-24 13:53
whaosoft-143的博客
针对不同类型任务(例如数学解答和证明、科学
问答
、推理解谜、主观对话等)进行了算法探索和初步集成验证,实现了多任务强化学习的混合训练。 构建基于结果奖励的强化学习新范式 OREAL...
51c大模型~合集159
2025-07-25 16:57
whaosoft-143的博客
,时长00:46 视频来源:tiktok 博主 @tkp..1001 「真人拍摄还是 AI 生成」,如果搁一年前,这个
问题
还很容易回答,因为细节处总有一眼 AI 的破绽,但现在,真与假的界限已变得愈发模糊。 越来越多「真实」的视频,...
【信息科学与工程学】【人工智能】【知识工程】企业知识库管理与评估——第二篇
2026-01-11 02:33
flyair_China的博客
隐性、经验性、情境性 图结构+文档库 隐性知识转化率、应用场景 过程性知识 流程性、操作性、时序性 流程图+状态机 流程完整性、执行效率 元知识 关于知识的知识 元数据框架 元数据完整性、质量控制 二、公司结构...
51c大模型~合集163
2025-08-03 14:38
whaosoft-143的博客
它解决的
问题
是:当 LLM 仅优化答案正确性时,其推理过程(如 Chain-of-Thought)变得难以被人类或小型模型理解和验证,导致「可解释性」下降。但在高风险应用中,用户需要能快速、准确判断模型输出是否正确,而不仅...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
5月8日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
4月30日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
4月23日

 分享
分享 系统已结题
5月8日
系统已结题
5月8日 已采纳回答
4月30日
创建了问题
4月23日
已采纳回答
4月30日
创建了问题
4月23日