
最近发现一个小问题,用spark_submit提交执行spark on yarn任务的时候,当任务结束,总是会收到org.apache.spark.SparkException报错,报错内容为当前任务在yarn上已结束,我就觉得很怪异,是我的配置问题吗?
正常来说任务结束不因是正常结束进程吗?
今天特意搞了一个小Demo,复现了这个问题,有没有朋友给一些提点。
首先代码是一个wordcount
object TestOnYarn {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("testyarn").getOrCreate()
session.sparkContext.setLogLevel("ERROR")
val da = session.sparkContext.parallelize(List("111", "222", "333"))
da.map((_,1)).reduceByKey(_+_).foreach(println(_))
session.stop()
}
}
我提交任务的命令如下
/opt/spark-2.1.1/bin/spark-submit --class other.TestOnYarn --master yarn --deploy-mode cluster --executor-memory 1g --executor-cores 1 --num-executors 1 /opt/gw.jar
当任务开始运行之后前面都很正常,但是最后一段就开始报错了
此处之前都是正常的输出
22/05/21 13:23:17 INFO Client: Application report for application_1653107941567_0002 (state: FAILED)
22/05/21 13:23:17 INFO Client:
client token: N/A
diagnostics: Application application_1653107941567_0002 failed 2 times due to AM Container for appattempt_1653107941567_0002_000002 exited with exitCode: -1000
For more detailed output, check application tracking page:http://hdp3:8088/cluster/app/application_1653107941567_0002Then, click on links to logs of each attempt.
Diagnostics: File does not exist: hdfs://hdp1/user/root/.sparkStaging/application_1653107941567_0002/gw.jar
java.io.FileNotFoundException: File does not exist: hdfs://hdp1/user/root/.sparkStaging/application_1653107941567_0002/gw.jar
at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1309)
at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1301)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1301)
at org.apache.hadoop.yarn.util.FSDownload.copy(FSDownload.java:253)
at org.apache.hadoop.yarn.util.FSDownload.access$000(FSDownload.java:63)
at org.apache.hadoop.yarn.util.FSDownload$2.run(FSDownload.java:361)
at org.apache.hadoop.yarn.util.FSDownload$2.run(FSDownload.java:359)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.yarn.util.FSDownload.call(FSDownload.java:358)
at org.apache.hadoop.yarn.util.FSDownload.call(FSDownload.java:62)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Failing this attempt. Failing the application.
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1653110584051
final status: FAILED
tracking URL: http://hdp3:8088/cluster/app/application_1653107941567_0002
user: root
Exception in thread "main" org.apache.spark.SparkException: Application application_1653107941567_0002 finished with failed status
at org.apache.spark.deploy.yarn.Client.run(Client.scala:1180)
at org.apache.spark.deploy.yarn.Client$.main(Client.scala:1226)
at org.apache.spark.deploy.yarn.Client.main(Client.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:743)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:187)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:212)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:126)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
22/05/21 13:23:17 INFO ShutdownHookManager: Shutdown hook called
22/05/21 13:23:17 INFO ShutdownHookManager: Deleting directory /tmp/spark-07bdc687-4c57-4c5c-9de5-1b0ba8b28ea0
我在yarn上看到的也是这个任务最终的状态是FAILED

但是!我用yarn logs命令拉去下任务日志却发现任务实际上已经成功结束了
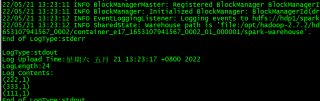
此外我去取spark的日志服务上也拉取了该任务的日志,日志上也是显示任务成功了

因此对前面提到的spark_submit日志输出报错的现象有些费解?





