爬虫Xpath路径使用出错
爬取一位用户ID名
import requests
from lxml import etree
import re
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/103.0.0.0 Safari/537.36'
}
res = requests.get('https://www.weibo.com', headers=headers)
selector = etree.HTML(res.text)
id = selector.xpath('//*[@id="scroller"]/div[1]/div[12]/div/article/div/header/div[1]/div/div[1]/a/span/text()')
print(id)
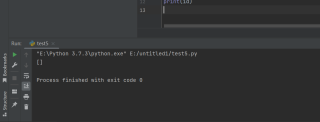
运行结果