
问题遇到的现象和发生背景
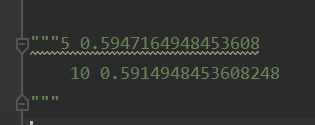
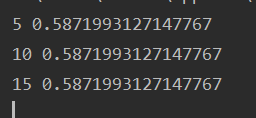
循环训练模型。我在循环训练模型的时候,随机打乱了训练数据,最后得到的结果都是一样的。我尝试单独运行5和10迭代次数,结果不一样。按理来说循环结果应该是不一样的,但是出现了结果完全相同的结果。
问题相关代码,请勿粘贴截图
# 随机选取训练集,并训练模型,并得到各个模型预测结果
def train_m(m):
"""
:param m: 设置模型数目
:return: 返回m个模型
"""
model = {} # 设置空的字典,用以存储模型或预测结果
pred = {}
i = 0
while i < m:
row_rand = np.random.permutation(train) # 打乱数据顺序(使链排序为随机)
row_rand_data = row_rand[..., 0:74]
row_rand_label = row_rand[..., 74:134]
# 训练模型,将所有模型存储在字典中
clf = ClassifierChain(LGBMClassifier())
clf_i = clf.fit(row_rand_data, row_rand_label)
clf_i_copy = copy.copy(clf_i)
model['%s'%i] = clf_i_copy
# 预测,将所有预测结果存储在字典中,并将结果转换为数组toarray()
pred_i = clf_i.predict(test_data).toarray()
pred_i_copy = copy.copy(pred_i)
pred['%s'%i] = pred_i_copy
i = i + 1
return model, pred
# 计算权重,得到最终预测结果
def w_pred_get(prediction_all, ft):
w = prediction_all['0']
num = 0
i = j = 0
# 统计预测标签数目
while i < np.shape(prediction_all['0'])[0]:
while j < np.shape(prediction_all['0'])[1]:
for value in prediction_all.values():
if value[i, j] == 1:
num = num + 1
w[i, j] = num
num = 0
j = j + 1
j = 0
i = i + 1
w = w/len(prediction_all) # 得到权值
# 设置阈值ft,得到最终预测结果
condition = w < ft
condition2 = w >= ft
prediction = np.where(condition, w, 1)
prediction = np.where(condition2, prediction, 0)
return prediction, w
# 查看不同迭代次数对于acc的影响,并进行可视化
for t in np.arange(5, 20, 5):
model_it, pred_it = train_m(t)
pred_w, w = w_pred_get(pred_it, 0.5)
Subset_Accuracy = accuracy_score(pred_w, test_label)
print(t, Subset_Accuracy)
t = t + 5






