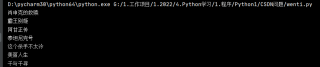
在使用requests爬网页信息时,没有报错,但是结果只显示“[]” 问题遇到的现象和发生背景
# coding=utf-8
import requests
import re
import pandas as pd
import xlwt
url='https://movie.douban.com/top250'
# 定义抓取函数--df.content
def get_content(url):
# 过滤无效信息
header ={
'User-Agent':'Mozilla5.0 (Windows NT 10.0; Win64; x64) AppleWebKit537.36 (KHTML, like Gecko) Chrome103.0.0.0 Safari537.36'
}
# 使用get方法获取网页响应信息
df=requests.get(url,headers=header)
# 展示响应信息全部内容
return df.content
print(df.content)
get_content(url)
# 固定定义获取函数--reslut
def get_text(url):
da = get_content(url)
# 使用正则表达式来提取信息
zz='''class=
span class=title>(.*)<span'''
compile = re.compile(zz)
# 使用正则在响应内容中匹配信息
result=re.findall(compile,str(da)) #要注意findall的时候要把要匹配的原内容格式调为str()#
return result
# 填入要抓取的网页响应内容
print(get_text(url))
names=get_text(url)
for name in names:
print(names)
# 现在显示的结果是【】!!!
# 保存到Excel
count = 0
workbook = xlwt.Workbook()
sheet = workbook.add_sheet(sheetname="汇总表")
for each in range(0, 100):
sheet.write(count, 0, names) # row, column, value
count = count + 1
workbook.save('Excel_test1.xls')
print("已完成")
运行结果及报错内容 :
[]
已完成
进程已结束,退出代码0
我的解答思路和尝试过的方法 :
1.刚开始以为是python解释器和环境变量的路径不对应导致的,但是试过了全部的python.exe的路径。都是一样的结果([])
2.后面怀疑是pycharm的结果显示问题,去了jupyter试,结果还是一样([])
我想要达到的结果:
找出为什么结果显示是[]的原因并解决。