问题遇到的现象和发生背景
每次获取章节的时候都会到第10个或者11个就报错检索超出列表范围 这是之前从博客复制过来的 然后根据网站重新分析修改的 然后还有一个问题 content函数中 遍历cont[0] 和 cont 输出的内容不一样 cont[0]文本类容中没有那些<>之类的东西 但是cont会出现很多 然后格式也有问题 好像遍历cont的时候不会出现报错 想问一下是哪个地方出现问题了 方便的话可以帮忙看一下 多谢
问题相关代码,请勿粘贴截图
import requests
import os
from bs4 import BeautifulSoup
import re
import urllib3
urllib3.disable_warnings()
url = 'https://quanxiaoshuo.com/182901/' # 网站路径
# 伪装请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
res = requests.get(url, headers=headers,verify=False)#发送请求
res.encoding = 'gbk' # 设置编码
# 使用BeautifulSoup解析页面
soup = BeautifulSoup(res.text, 'html.parser')
# BeautifuSoup支持css选择器,借此得到指定标签
# 得到作者
book_info = soup.select('body > div.text.t_c > h1 > a:nth-child(1) ,body > div:nth-child(3) > div.f_l.t_c.w2 > a')
book_name = book_info[0].text #书名
book_author = book_info[1].text #作者名
#print(book_author)
# 设置保存路径
root_path = os.path.abspath(os.path.dirname(__file__)) # 得到当前文件路径
save_path = os.path.join(root_path, book_name+'.txt')
# 取得章节
chapters = soup.select(' a ') #查找a标签,获得章节信息
#print(count(chapters))
list_num=re.findall(r'\d{8}.', str(chapters))
# print(list_num) #章节编号
# 循环打印
# for chapter in chapters:
# print(chapter.text) # 打印章节名和连接地址
# 定义一个方法得到具体章节的内容
# 定义一个变量判断是爬取此章节
isreq = True
def content(url_last):
# 当前章节的url等于书籍的url加上章节a标签的href
global url,headers,isreq
if isreq:
# 判断是否到第一章了
if '21427207' in str(url_last):
isreq = False
else:
return
url_now = url + url_last
# print(url_now)
#爬取具体章节内容
res_chap = requests.get(url_now, headers=headers,verify=False)
res_chap.encoding = 'gbk'
soup = BeautifulSoup(res_chap.text, 'html.parser')
cont1 = soup.select('.t_c')
cont = soup.select('#content')
con = '\n' + str(cont1) + '\n' ## 使用一个变量来储存单章内容,第一行是文章标题
print(cont)
# # 处理文章内容
for text in cont[0]: # soup的select方法返回的是一个列表,所以cont[0]才是我们想要的具体内容,使用for循环得到每一行
# 去除换行标签
if str(text) == '
':
con += '\n'
else:
con += str(text)
print(con)
return con
# 定义保存文件的方法
# 首先写入书名和作者
with open(save_path, 'w', encoding='utf-8') as w:
w.write(book_name+'\n'+book_author)
def save_book(content):
if content == None:
return
with open(save_path, 'a', encoding='utf-8') as f:
f.write(content)
# # 循环章节列表爬取并保存
for chapter in list_num:
cont = content(chapter)
save_book(cont)
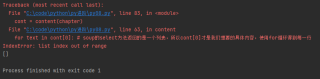
运行结果及报错内容