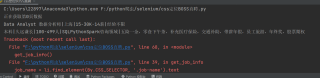
用selenium爬取数据css定位元素也没问题,都正常打印输出了,然后又报错说找不到元素
我也添加等待时间了,元素也不在frame中,希望指点一下
from selenium.webdriver import Chrome
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import pandas as pd
web = Chrome() # 实例化一个浏览器对象
url = "https://www.zhipin.com/?ka=header-home"
web.get(url)
web.maximize_window()
web.implicitly_wait(10)
# time.sleep(3)
data = {
'职位名称': [],
'工作地址': [],
'岗位薪资': [],
'经验要求': [],
'公司名称': [],
'公司规模': [],
'技能要求': [],
'公司福利': []
}
# 通过css选择器定位元素
web.find_element(By.CSS_SELECTOR, '.ipt-search').send_keys('数据分析', Keys.ENTER)
web.implicitly_wait(30) # 隐式等待 等浏览器数据加载完成后 就进行下一步操作
# time.sleep(3)
def get_job_info():
li_list = web.find_elements(By.CSS_SELECTOR, '.job-list-box li')
for li in li_list:
job_name = li.find_element(By.CSS_SELECTOR, '.job-name').text
job_address = li.find_element(By.CSS_SELECTOR, '.job-area').text
price = li.find_element(By.CSS_SELECTOR, '.salary').text
yaoqiu = li.find_element(By.CSS_SELECTOR, '.job-info .tag-list').text
company_name = li.find_element(By.CSS_SELECTOR, '.company-info .company-name a').text
# company_type = li.find_element(By.CSS_SELECTOR, '.company-info ul li:nth-child(1)').text
# company_rongzi = li.find_element(By.CSS_SELECTOR, '.company-info ul li:nth-child(2)').text
company_size = li.find_element(By.CSS_SELECTOR, '.company-info ul li:nth-child(3)').text
job_skill = li.find_element(By.CSS_SELECTOR, '.job-card-footer .tag-list').text
fuli = li.find_element(By.CSS_SELECTOR, '.info-desc').text
print(job_name, job_address, price, yaoqiu, company_name, company_size, job_skill, fuli, sep='|')
data['职位名称'].append(job_name)
data['工作地址'].append(job_address)
data['岗位薪资'].append(price)
data['经验要求'].append(yaoqiu)
data['公司名称'].append(company_name)
data['公司规模'].append(company_size)
data['技能要求'].append(job_skill)
data['公司福利'].append(fuli)
df = pd.DataFrame(data)
df.to_excel('SF.xlsx', index=False)
web.find_element(By.CSS_SELECTOR, '.ui-icon-arrow-right').click()
for i in range(3):
print(f'正在获取第{i}页数据')
web.implicitly_wait(30)
# time.sleep(5)
get_job_info()
web.quit() # 自动关闭浏览器
print("爬取完毕!")