
关于mysql中的数据导入hive的一些问题 ERROR tool.ImportTool: Encountered IOException running import job: java.io.IOException: Hive exited with status 1
查了相关的一些解决办法 缺少JAR包之类的都试过 试之前下面的代码都没有问题 不知道为什么上面的代码始终都报错 求大神指导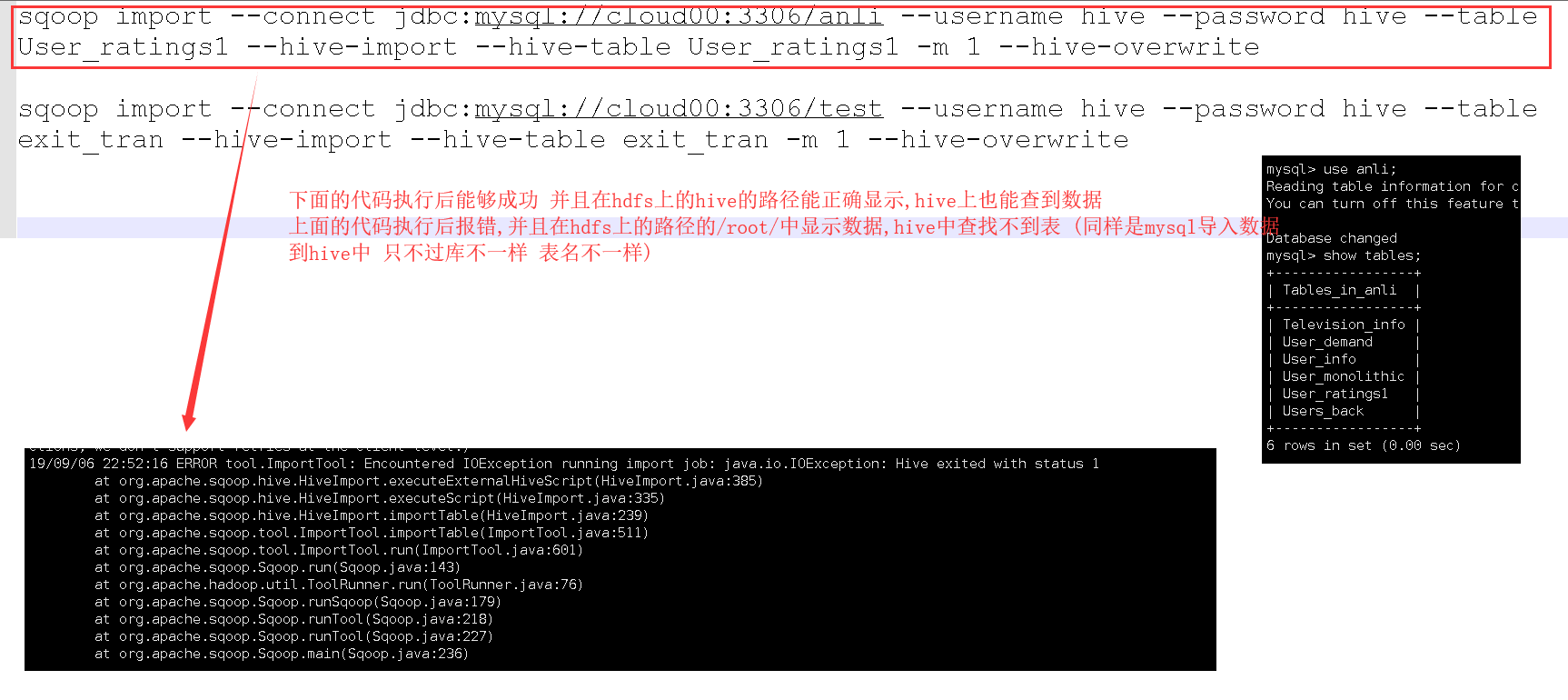
sqoop import --connect jdbc:mysql://cloud00:3306/anli --username hive --password hive --table User_ratings1 --hive-import --hive-table User_ratings1 -m 1 --hive-overwrite
```sqoop import --connect jdbc:mysql://cloud00:3306/test --username hive --password hive --table exit_tran --hive-import --hive-table exit_tran -m 1 --hive-overwrite





