问题遇到的现象和发生背景
用DolphinScheduler调度调用Shell脚本,Shell脚本内调用的是Hql脚本,Hql的作用是从es拉取数据到hive。
代码
#!/bin/bash
hive=/opt/cloudera/parcels/CDH/lib/hive/bin/hive
dateTime=2022.10.19
dt=20221019
ES_NODE=10.6.111.162:9200,10.6.111.163:9200,10.6.111.164:9200,10.6.111.228:9200,10.6.112.219:9200,10.6.112.220:9200
ES_USER=developer6
ES_PASSWD=p7anxylcSRVRRyzwIybL
sql="
add jar hdfs://TdpHdfsCluster/user/tdp/jars/hive/elasticsearch-hadoop-7.17.5.jar;
drop table if exists xll.op_tmp_base_es_${dt};
create table xll.op_tmp_base_es_${dt} (
waybillno string,
opcode bigint,
pdadevicetype string,
sourceip string,
requesturi string,
pdadeviceno string,
pdaversionno string
)
ROW FORMAT SERDE 'org.elasticsearch.hadoop.hive.EsSerDe'
stored by 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES(
'es.nodes' = '111.6.111.162:9200,111.6.111.163:9200,111.6.111.164:9200,111.6.111.228:9200,111.6.112.219:9200,111.6.112.220:9200',
'es.index.auto.create' = 'false',
'es.resource' = 'exp_pda_op_log-${dateTime}/_doc',
'es.net.http.auth.user' = 'esUser',
'es.net.http.auth.pass' = '1234567',
'es.read.metadata' = 'true',
'es.mapping.id' = 'id',
'es.mapping.names'='waybillno:waybillNo,opcode:opCode,pdadevicetype:pdaDeviceType,sourceip:sourceIp,requesturi:requestURI,pdadeviceno:pdaDeviceNo,pdaversionno:pdaVersionNo'
);
create table if not exists xll.dim_op_base_hive_1(
waybillno string,
opcode bigint,
pdadevicetype string,
sourceip string,
requesturi string,
pdadeviceno string,
pdaversionno string
)
partitioned by (dt string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://TdpHdfsCluster/user/hive/warehouse/xll.db/source/dim_op_base_hive_1';
set hive.exec.reducers.bytes.per.reducer=256000000;
set hive.exec.reducers.max=20;
insert overwrite table xll.dim_op_base_hive_1 partition(dt = '${dt}')
select * from xll.op_tmp_base_es_${dt} limit 10;
drop table if exists xll.op_tmp_base_es_${dt};
"
echo "当前日期为:${dateTime},分区时间为:${dt}"
echo "es集群节点为:${ES_NODE},用户名为:${ES_USER},密码为:${ES_PASSWD}"
$hive -e "$sql"
运行结果及报错内容
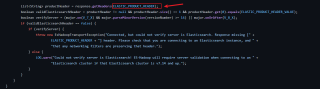
[INFO] 2022-10-21 16:32:18.881 TaskLogLogger-class org.apache.dolphinscheduler.plugin.task.shell.ShellTask:[66] - -> 22/10/21 16:32:18 WARN rest.RestClient: Could not verify server is Elasticsearch! ES-Hadoop will require server validation when connecting to an Elasticsearch cluster if that Elasticsearch cluster is v7.14 and up.
翻译:RestClient:无法验证服务器是Elasticsearch!如果Elasticsearch集群是v7.14及以上版本,ES-Hadoop在连接到该Elasticsearch集群时将需要服务器验证。

sql脚本在dbeaver上是可以运行的,也没有连接es的问题。
期望
希望脚本可以运行成功。