要么报错,要么输出error
遇到的现象和发生背景,请写出第一个错误信息
package 设计实验;
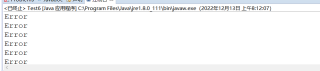
我不知到问题出在哪
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
import java.util.regex.Pattern;
/**
* 通过URL读取页面内容
* */
public class Test6 {
// 爬取网页源代码
public void get_html(String urls) {
try {
//创建一个URL实例
URL url = new URL(urls);
try {
//通过URL的openStrean方法获取URL对象所表示的自愿字节输入流
InputStream str = url.openStream();
InputStreamReader str1 = new InputStreamReader(str,"utf-8");
//为字符输入流添加缓冲
BufferedReader br = new BufferedReader(str1);
String data = br.readLine();//读取数据
String html="";
while (data!=null){//循环读取数据
html +=data;
data = br.readLine();
}
// System.out.println(html);
br.close();
str1.close();
str.close();
get_text(html); // 执行get_text,获得正文
} catch (IOException e) {
e.printStackTrace();
}
} catch (MalformedURLException e) {
e.printStackTrace();
}
}
// 将网页源代码中的所有文本信息提取出来
public void get_text(String text) throws FileNotFoundException {
String htmlStr = text; // 含html标签的字符串
String textStr = "";
java.util.regex.Pattern p_script;
java.util.regex.Matcher m_script;
java.util.regex.Pattern p_style;
java.util.regex.Matcher m_style;
java.util.regex.Pattern p_html;
java.util.regex.Matcher m_html;
try {
String regEx_script = "<[\\s]*?script[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?script[\\s]*?>"; // 定义script的正则表达式{或<script[^>]*?>[\\s\\S]*?<\\/script>
String regEx_style = "<[\\s]*?style[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?style[\\s]*?>"; // 定义style的正则表达式{或<style[^>]*?>[\\s\\S]*?<\\/style>
String regEx_html = "<[^>]+>"; // 定义HTML标签的正则表达式
p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); // 过滤script标签
p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); // 过滤style标签
p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); // 过滤html标签
textStr = htmlStr;
} catch (Exception e) {System.err.println("Html2Text: " + e.getMessage()); }
//剔除空格行
textStr=textStr.replaceAll("[ ]+", " ");
textStr=textStr.replaceAll("(?m)^\\s*$(\\n|\\r\\n)", "");
textStr = textStr.replaceAll("[^a-z^A-Z]", " ");
//System.out.println(textStr);
refine_word1(textStr);
refine_letter(textStr);
}
public void refine_word1(String text) throws FileNotFoundException {
Scanner scanner=new Scanner(text);
//单词和数量映射表
HashMap<String, Integer > hashMap=new HashMap<String,Integer>(); // 显示频数
System.out.println("文章-----------------------------------");
while(scanner.hasNextLine())
{
String line=scanner.nextLine(); // Scanner接受文件流为一个字符串
System.out.println(line);
//\W+ : 匹配所有非单词
String[] lineWords=line.split("\\W+");//用非单词符来做分割,分割出来的就是一个个单词
Set<String> wordSet = hashMap.keySet(); // 用于显示单词
for(int i=0;i<lineWords.length;i++)
{
//如果已经有这个单词了
if(wordSet.contains(lineWords[i]))
{
int number=hashMap.get(lineWords[i]);
number++;
hashMap.put(lineWords[i], number);
}
else
{
hashMap.put(lineWords[i], 1); //put设置键为单词本身,后面参数为它的值
}
}
}
System.out.println("统计单词:------------------------------");
//hashMap.keySet().iterator(); 返回hash里面的全部key的集合,然后去除重复的元素
Iterator<String> iterator=hashMap.keySet().iterator();
while(iterator.hasNext())
{
try {
OutputStreamWriter files = new OutputStreamWriter(new FileOutputStream("bin\\unit8\\words.txt",true),"UTF-8");
String word=iterator.next();
files.write("单词:"+word+"\t\t\t"+"出现次数:"+hashMap.get(word)+"\n");
files.flush();
System.out.printf("单词:%-12s 出现次数:%d\n",word,hashMap.get(word));
files.close();
}catch(IOException e) {
System.out.println("Error");
}
}
System.out.println("程序结束--------------------------------");
}
public void refine_letter(String str)
{
str = str.toLowerCase();
Scanner scanner=new Scanner(str);
//单词和数量映射表
HashMap<Character, Integer > hashMap=new HashMap<Character,Integer>(); // 显示频数
Set<Character> wordSet = hashMap.keySet(); // 用于显示单词
for(int i=0;i<str.length();i++)
{
//如果已经有这个单词了
if(wordSet.contains(str.charAt(i)))
{
int number=hashMap.get(str.charAt(i));
number++;
hashMap.put(str.charAt(i), number);
}
else
{
hashMap.put(str.charAt(i), 1); //put设置键为单词本身,后面参数为它的值
}
}
System.out.println("统计字母:------------------------------");
//hashMap.keySet().iterator(); 返回hash里面的全部key的集合,然后去除重复的元素
Iterator<Character> iterator=hashMap.keySet().iterator();
while(iterator.hasNext())
{
try {
OutputStreamWriter files = new OutputStreamWriter(new FileOutputStream("bin\\unit8\\letter.txt",true),"UTF-8");
Character word=iterator.next();
files.write("字母:"+word+"\t\t\t"+"出现次数:"+hashMap.get(word)+"\n");
files.flush();
System.out.printf("字母:%-12s 出现次数:%d\n",word,hashMap.get(word));
files.close();
}catch(IOException e) {
System.out.println("Error");
}
}
System.out.println("程序结束--------------------------------");
}
public static void main(String[] args){
String url = "https://github.com/";
Test6 start = new Test6();
start.get_html(url);
}
}










