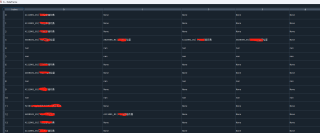
CODE2中的内容是由一段编码+“|“+中文名称,但是其中可能有很多编码及其所属的中文,并被逗号分开,像第4行那样。现在想把CODE2中的所有编码保留下来,并分别变成名字1,2,3,4,5等等,编码的中文意义删掉。
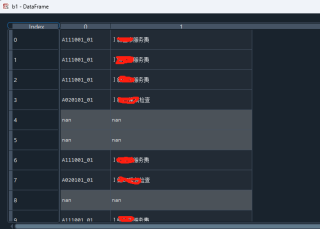
我的思路:先把”逗号和“|”分号拆掉,并且自动分列,再把其中的中文意义列再drop掉
刚开始用split,但是split函数只能删除一个分隔符。之后使用rsplit函数,但是用了之后发现rsplit 不管怎么,都无法成功一下分解2个分隔符。
代码如下
c=a['code2'].str.rsplit('[,|]',expand=True)
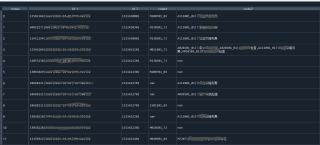
运行结果及详细报错
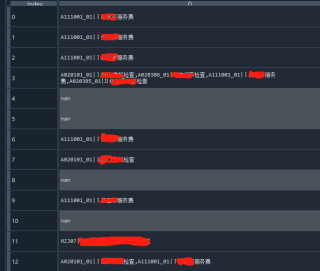
我尝试了一下,需要好几个步骤
a=a['code2'].str.rsplit(',',expand=True)
c=a['code2'].rsplit('[,|]',expand=True)
b=a['code2'].str.split(',',expand=True)
b1=b[0].str.split('|',expand=True)
但是问题是如果这样做的话,原本与其相匹配的id_1和id_2就不见了,而起一起只能处理其中其中一列,如果有10列,过程过于繁琐。有没有简单的办法,又能直接从原来的表直接自动生成相关列?