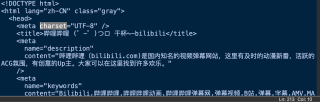
网站名称不能写出来,要不然会因为被认为侵权而发布不了问题
写了一个最基础的爬虫去访问某网站(加了请求头),状态码200,爬出来的网页源代码是一段乱码
代码(原文件已经删了):
import requests
url='https://www.douban.com'
headers={中间是什么忘了,总之包含了User-agent和Referer}
r=requests.get(url,headers=headers)
r.text.encode('utf=8')
print(r.statu_code)
print(r.text)
成功访问,r.text是一大段的乱码?
爬取某网站的原文件已经给我删了,以同样的方法访问另一个网站首页是一部分乱码,用浏览器看了一下网页源代码,发现乱码部分好像大多在引号内
把r.text写进html文件里(utf-8转gbk):
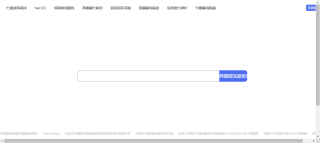
还有这个(utf-8):
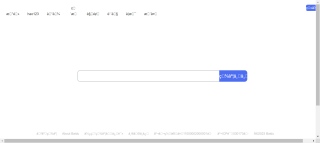
加encode('gbk')无法转换
还有我把这个程序改动了去爬某个视频网站首页,
https://www.bilibili.com
用了网上介绍的几种反反爬,出来的只有一小块,是源代码真就这么点,还是它设置了其他反爬?
(网页名称只能这么写了,不然不让提交)