

最近用的webmagic做垂直爬虫,对方网页是通过js动态加载,不能直接爬html的,所以是从F12里面的Network,抓包拿到网址,再发送请求拿到的数据。
因为要做请求排序,我模仿了PriorityScheduler,自定义了一个Scheduler:
下面的代码里面:
level:记录爬取深度
pageNum:记录分页的页码
literatureNum:记录文章的顺序
textIndex:记录全文的内容(因为全文是分开很多个图片,上面无页码,所以从第一页到最后一页,要记录)
爬取的逻辑是,先有pageNum,再有literatureNum,最后有textIndex,
但爬虫顺序优先级是textIndex>literatureNum>pageNum。
对应的深度:pageNum的level是0,literatureNum的level是1,textIndex的level是2
用的PriorityBlockingQueue做任务队列:
package com.huada.priorityScheduler;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.scheduler.DuplicateRemovedScheduler;
import us.codecraft.webmagic.scheduler.MonitorableScheduler;
import java.util.concurrent.PriorityBlockingQueue;
/**
* Priority scheduler. Request with higher priority will poll earlier. <br>
*
* @author code4crafter@gmail.com <br>
* @since 0.2.1
*/
public class MyQueueScheduler extends DuplicateRemovedScheduler implements MonitorableScheduler {
public static final int INITIAL_CAPACITY = 100;
private final PriorityBlockingQueue<Request> priorityQueue = new PriorityBlockingQueue<>(INITIAL_CAPACITY, (o1, o2) -> {
//比较优先级,越大越优先
if ((int) o1.getExtra("level") != (int) o2.getExtra("level")) return (int) o2.getExtra("level") - (int) o1.getExtra("level");
//比较页数,页数越小越优先
if ((int) o1.getExtra("pageNum") != (int) o2.getExtra("pageNum")) return (int) o1.getExtra("pageNum") - (int) o2.getExtra("pageNum");
//比较文章顺序,文章顺序越前(小)越优先
if ((int) o1.getExtra("literatureNum") != (int) o2.getExtra("literatureNum")) return (int) o1.getExtra("literatureNum") - (int) o2.getExtra("literatureNum");
//比较全文图片索引,索引越小越优先
if ((int) o1.getExtra("textIndex") != (int) o2.getExtra("textIndex")) return (int) o1.getExtra("textIndex") - (int) o2.getExtra("textIndex");
return 0;
});
@Override
public void pushWhenNoDuplicate(Request request, Task task) {
priorityQueue.put(request);
}
@Override
public synchronized Request poll(Task task) {
return priorityQueue.poll();
}
@Override
public int getLeftRequestsCount(Task task) {
return priorityQueue.size();
}
@Override
public int getTotalRequestsCount(Task task) {
return getDuplicateRemover().getTotalRequestsCount(task);
}
}
但是最后的排序结果很诡异,排序很乱,不知道为什么:
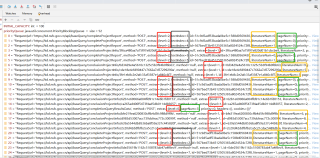
后面我不用PriorityBlockingQueue,用的CopyOnWriteArrayList,排序则正常,结果如下:
package com.huada.priorityScheduler;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.scheduler.DuplicateRemovedScheduler;
import us.codecraft.webmagic.scheduler.MonitorableScheduler;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* 自定义任务队列
*/
public class MyArrayListScheduler extends DuplicateRemovedScheduler implements MonitorableScheduler {
private static CopyOnWriteArrayList<Request> priorityList = new CopyOnWriteArrayList<>();
@Override
public void pushWhenNoDuplicate(Request request, Task task) {
priorityList.add(request);
}
@Override
public synchronized Request poll(Task task) {
if (priorityList.size() == 0) return null;
if (priorityList.size() >= 2) {
priorityList.sort((o1, o2) -> {
//比较优先级,越大越优先
if ((int) o1.getExtra("level") != (int) o2.getExtra("level")) return (int) o2.getExtra("level") - (int) o1.getExtra("level");
//比较页数,页数越小越优先
if ((int) o1.getExtra("pageNum") != (int) o2.getExtra("pageNum")) return (int) o1.getExtra("pageNum") - (int) o2.getExtra("pageNum");
//比较文章顺序,文章顺序越前(小)越优先
if ((int) o1.getExtra("literatureNum") != (int) o2.getExtra("literatureNum")) return (int) o1.getExtra("literatureNum") - (int) o2.getExtra("literatureNum");
//比较全文图片索引,索引越小越优先
if ((int) o1.getExtra("textIndex") != (int) o2.getExtra("textIndex")) return (int) o1.getExtra("textIndex") - (int) o2.getExtra("textIndex");
return 0;
});
}
Request req = priorityList.get(0);
priorityList.remove(0);
return req;
}
@Override
public int getLeftRequestsCount(Task task) {
return priorityList.size();
}
@Override
public int getTotalRequestsCount(Task task) {
return getDuplicateRemover().getTotalRequestsCount(task);
}
}
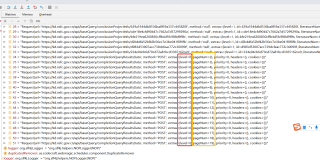
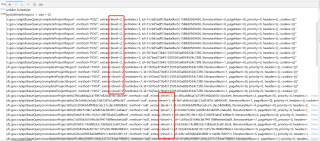
所以用PriorityBlockingQueue为什么会出现排序失灵的情况?





