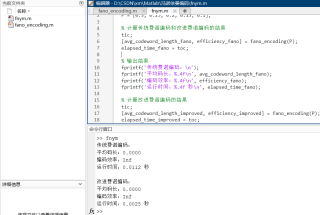
利用matlab实现传统费诺编码和改进费诺编码,改进费诺编码算法思想如下:
通过对费诺编码算法以及算例的研究,费诺编码存在的主要问题是编码结果可能会出现概率大的符号对应长码,而概率小的符号对应短码的情况,如表2-10中、对应的码字,这就会造成信源符号在编码过程中产生不同程度的冗余,增加平均码长,降低编码效率。费诺编码相较香农编码仍有很高的编码效率,但是和霍夫曼编码仍有一定的差距,因此应用也不及霍夫曼编码应用广泛。
改进的费诺编码步骤如下:
(1)设信源符号为X,对信源符号从大到小进行降序排列;
(2)将信源符号集(i=1,2,⋯,n)按其概率大小分成两个分组,使每个分组的概率之和尽可能接近或者相等,令第一个子集的编码为“0”,第二个子集的编码为“1”,作为代码组的第一个码元;
(3)按照相同的原则,对分组做第二次分解,同样分解成两个分组,并使两个分组的概率和尽可能接近或者相等,再把第一个分组编码为“0”,第二个分组编码为“1”,作为代码组的第二个码元;
(4)重复上述步骤,直到各分组仅包含一个信源符号为止;
(5)将逐次分解过程当中得到的码元排列起来,得到信源符号的初始码字;
(6)将所有码字按照码长长短进行升序排列进行排序,其中第 i 个码字记作,就是各消息符号 所对应的码字。
结果显示各自编码结果,编码效率,平均码长以及各自运行时间,希望各位参考该gpt时能够运行一下。

关于#matlab#的问题,如何解决?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

7条回答 默认 最新

- 2025-11-26 04:30MATLAB具有简单易学的特点,其编程语言被称为M语言,它是一种基于矩阵的操作语言,语法结构简洁明了,使得用户可以快速上手并解决复杂的问题。 本书《MATLAB编程与问题解决》系统性地介绍了MATLAB的编程基础及其在...
- 2024-06-19 16:04MATLAB是一个多范式数值计算环境和编程语言,主要用于工程计算、数据分析、算法开发以及科学图形。它的名字来源于"Matrix Laboratory"(矩阵实验室),最初是为矩阵运算而开发的。MATLAB提供了丰富的内置函数和工具...
- 2024-01-11 16:50第 7 章:使用 MATLAB 编程 第 8 章:输入、输出和运算符 第 9 章:流程控制语句 第 10 章:数学函数 第11章:弦乐 第12章:情节 第 13 章:图形和图形用户界面编程 第 14 章:使用 MATLAB 进行自相关 第 15 章:...
- 2022-11-24 05:10MATLAB是一种强大的数值计算和符号计算软件,广泛应用于科学计算、数据分析、工程设计等领域。它以其简洁的语法、丰富的...通过课程的学习,学生将能够运用MATLAB解决实际工程问题,进一步提高他们的科研和工程能力。
- 2024-06-16 12:17**基于MATLAB编程语言实现DTW算法源代码** 动态时间规整(Dynamic Time Warping, 简称DTW)是一种非线性时间序列匹配算法,广泛应用于语音识别、信号处理、模式识别等领域。MATLAB作为强大的数值计算和数据可视化...
- 2024-04-16 01:17- **接近自然语言的语法**:Matlab采用了一种类似于英语的高级编程语言,其语法简洁明了,易于理解和学习。 - **内置函数丰富**:Matlab拥有大量的内置函数,这些函数涵盖了从基础数学运算到高级算法的各种功能,...
- 2024-05-16 08:43本资料包“matlab用不同编程语言实现的各种Project Euler问题的解决方案.zip”专注于MATLAB语言,通过一系列源码实例,展示了如何利用MATLAB高效地解决这些问题。 MATLAB是一种交互式的计算环境,特别适合数值分析...
- 2024-06-02 20:39- **跨语言兼容性**: 支持与其他编程语言如C、Java等的交互。 #### 四、MATLAB的应用领域 **MATLAB**在多个领域有着广泛的应用: - **工程计算**: 如机械工程、航空航天工程等。 - **控制设计**: 包括自动控制...
- 2024-09-10 17:09Matlab(矩阵实验室)是一种高性能的数值计算环境和第四代编程语言,广泛应用于工程计算、数据分析、算法开发等领域。Matlab以其简单易用的编程方式和丰富的内置函数库深受工程师和科研人员的青睐。在实际工作中,...
- 2023-09-18 10:10- **模型构建**: 学习如何使用MATLAB解决实际问题,如优化问题、微分方程求解等。 - **模拟仿真**: 利用Simulink工具箱进行系统动态行为的模拟。 **3.2 神经网络优化算法** - **神经网络基础**: 了解神经元、层...
- 没有解决我的问题, 去提问

问题事件
 系统已结题
3月27日
系统已结题
3月27日 已采纳回答
3月19日
已采纳回答
3月19日-
赞助了问题酬金15元
3月18日
-
创建了问题
3月18日