

<select id="listUser" resultType="hexie.practice.learn.elasticsearch.entity.User">
SELECT id, user_name, mobile, address FROM user LIMIT 0,#{size}
</select>
@Autowired
private UserMapper userMapper;
@Test
void test() {
long l = System.currentTimeMillis();
List<User> users = userMapper.listUser(7000000);
long l1 = System.currentTimeMillis();
System.out.println("耗时: " + (l1 - l) + "ms");
System.out.println(users.size());
// 215ms 247ms 292ms 490ms 2883ms 18500ms 62423ms
// 100 1000 10000 100000 1000000 5000000 7000000
}
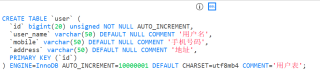
我有一张表user, 里面有一千万个数据, 没加索引, 查询100个数据的时候花费了215ms, 1000个数据247ms, 10000个数据292ms, 如上所示, 为什么花费的时间不是简单的后面加个0?
而且在十万数据量之前, 都是按照差不多1.2的比例增长, 但从1百万开始就是6倍增长, 5百万和7百万的用时差了3.4倍, 为什么会出现这样的情况?

直接在Navicat里查的话, 1千万数据都不用8秒, 为什么放到代码里就要花费这么长时间?









