
王博士,我想问一下,fine-tuning的边界一般在哪里。要让gpt学习行业知识,用fine-tunning是否够


1条回答 默认 最新

 关注
关注- 这篇博客: GPT原理介绍中的 2.2 fine-tuning(有监督) 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
当语言模型训练结束后,就可以将其迁移到具体的NLP任务中,假设将其迁移到一个文本分类任务中,记此时的数据集为C\mathcal{C}C,对于每一个样本,其输入为x1,…,xmx^{1}, \ldots, x^{m}x1,…,xm,输出为yyy。对于每一个输入,经过预训练后的语言模型后,可以直接选取最后一层Transformer最后一个时间步的输出向量hlmh_{l}^{m}hlm,然后在其后面接一层全连接层,即可得到最后的预测标签概率:
P(y∣x1,…,xm)=softmax(hlmWy) P\left(y | x^{1}, \ldots, x^{m}\right)=\operatorname{softmax}\left(h_{l}^{m} W_{y}\right) P(y∣x1,…,xm)=softmax(hlmWy)
其中,WyW_{y}Wy为新引入的全连接层的参数矩阵。因此,可以得到在分类任务中的目标函数:
L2(C)=∑(x,y)logP(y∣x1,…,xm) L_{2}(\mathcal{C})=\sum_{(x, y)} \log P\left(y | x^{1}, \ldots, x^{m}\right) L2(C)=(x,y)∑logP(y∣x1,…,xm)
在具体的NLP任务中,作者在fine-tuning时也把语言模型的目标引入到目标函数中,作为辅助函数,作者发现这样操作可以提高模型的通用能力,并且加速模型收敛,其形式如下:
L3(C)=L2(C)+λ∗L1(C) L_{3}(\mathcal{C})=L_{2}(\mathcal{C})+\lambda * L_{1}(\mathcal{C}) L3(C)=L2(C)+λ∗L1(C) 其中,λ\lambdaλ一般取0.5。可以发现,在fine-tuning阶段,此时新增的参数只有最后一层全连接层的参数WyW_{y}Wy,这比ELMo算法要容易得多。
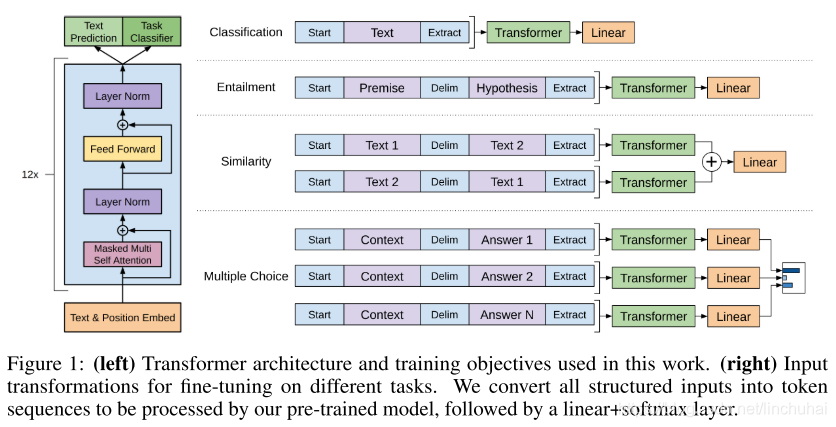
不过,上面这个例子只是对于文本分类任务,如果是对于其他任务,比如文本蕴涵、问答、文本相似度等,那么GPT该如何进行微改呢?针对这几种情况,作者提出了以下的修改方法:
- 文本蕴涵:对于文本蕴涵任务,作者用一个“$”符号将文本和假设进行拼接,并在拼接后的文本前后加入开始符“start”和结束符“end”,然后将拼接后的文本直接传入预训练的语言模型,在模型再接一层线性变换和softmax即可。
- 文本相似度:对于文本相似度任务,由于相似度不需要考虑两个句子的顺序关系,因此,为了反映这一点,作者将两个句子分别与另一个句子进行拼接,中间用“$”进行隔开,并且前后还是加上起始和结束符,然后分别将拼接后的两个长句子传入Transformer,最后分别得到两个句子的向量表示hlmh_{l}^{m}hlm,将这两个向量进行元素相加,然后再接如线性层和softmax层。
- 问答和常识推理:对于问答和常识推理任务,首先将背景信息与问题进行拼接,然后再将拼接后的文本依次与每个答案进行拼接,最后依次传入Transformer模型,最后接一层线性层得多每个输入的预测值。
具体的方法可以查看下图,可以发现,对这些任务的微改主要是新增线性层的参数以及起始符、结束符和分隔符三种特殊符号的向量参数。
解决 无用评论 打赏举报 分享
分享- 这篇博客: GPT原理介绍中的 2.2 fine-tuning(有监督) 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 2023-01-18 19:11在自然语言处理(NLP)领域,人工智能的发展日新月异,其中GPT...这种方法不仅推动了AI技术的进步,也为后续的预训练模型如GPT-2、GPT-3等奠定了基础,进一步推动了人工智能在理解和生成自然语言方面的边界。
- 2025-05-15 20:38AGI大模型与大数据研究院的博客 本文的目的就是深入探讨AI原生应用的伦理边界在哪里,范围涵盖了AI原生应用在各个领域可能出现的伦理问题。本文首先介绍相关的核心概念,让大家对AI原生应用和伦理边界有清晰的认识。接着分析核心概念之间的关系,...
- 2024-04-10 19:21标题中的“人工智能行业从CHAT-GPT到生成式AI(GenerativeAI):人工智能新范式,重新定义生产力”揭示了当前AI领域的热点话题,即从对话式AI模型如CHAT-GPT到更广泛的生成式AI技术的发展,以及这些技术对生产力的深远...
- 2025-07-15 23:1600&00的博客 其核心思想仍然基于自回归 Transformer 解码器架构,但在训练数据、模型参数、能力边界、稳定性和推理能力方面做了大幅优化。项目描述发布机构OpenAI架构类型Transformer Decoder(自回归)支持模态文本 + 图像(多...
- 2024-07-01 21:06xziyuan的博客 OpenAI作为一家全球领先的人工智能公司,在推动人工智能技术的边界上发挥着重要作用,其在大模型方面的研究和应用也是一直处于领先地位。本文将介绍 Open AI 多模态大模型的研究成果和应用,探讨其在人工智能领域的...
- 2024-12-01 23:52张彦峰ZYF的博客 主要涵盖了ChatGPT的背景、NLP学习范式的演进、预训练方法的详细介绍以及OpenAI的GPT系列模型的概述。旨在提供一个全面的认知和理解,以帮助读者更好地了解ChatGPT以及与之相关的NLP领域的发展。
- 2023-04-04 09:38《OpenAI 闭门讨论会V3纪要GPT-4.pdf》的文件记录了一场针对OpenAI最新发布的多模态预训练大模型GPT-4的深入讨论。以下是基于文件内容提炼的关键知识点: 1. **模型能力演变和边界**: - GPT-4的发布标志着大模型...
- 2025-06-13 20:08AI大模型-海文的博客 未来,随着算法优化与硬件升级,预训练技术将在更多领域释放潜力,但如何平衡性能、成本与伦理问题仍需持续探索。人工智能大模型(如ChatGPT、DeepSeek等)正驱动着技术变革,掌握相关技术已成为提升竞争力的关键。...
- 2024-12-01 16:15GPT技术,即生成式预训练变换器(Generative Pre-trained Transformer),是当下人工智能领域的一项重大技术突破。它以语言模型为基础,经历了数十年的发展,逐渐成为学术界和工业界关注的焦点。GPT技术的应用广泛,...
- 2025-09-10 22:46全栈你个大西瓜的博客 关于大模型的量化指标,较为普遍的有 [PPL],[BPC]等,可以简单理解为在生成结果和目标文本之间的 Cross Entropy Loss 上做了一些处理,这种方式可以用来评估模型对「语言模板」的拟合程度即给定一段话,预测后面可能...
- 没有解决我的问题, 去提问


问题事件
 创建了问题
4月27日
创建了问题
4月27日