
从云南大学校园网上下载一段关于云南大学的介绍文本,将文本保存在名称为“云南大学.txt”文本文件中,注意保存时文件编码要选“UTF-8”。编写程序完成对“云南大学.txt”文件中词汇的出现次数的统计,要求将长度为1的词去掉,并去掉'高校','大学'两个词,按各词出现次数从高到低排序后输出前20项。


从云南大学校园网上下载一段关于云南大学的介绍文本,将文本保存在名称为“云南大学.txt”文本文件中,注意保存时文件编码要选“UTF-8”。编写程序完成对“云南大学.txt”文件中词汇的出现次数的统计,要求将长度为1的词去掉,并去掉'高校','大学'两个词,按各词出现次数从高到低排序后输出前20项。
 分享
分享
jieba实现,应该符合你的要求:
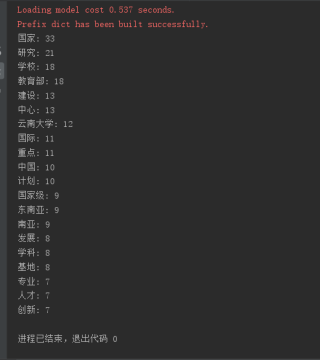
import jieba
from collections import Counter
# 打开文件
with open('云南大学.txt', 'r', encoding='utf-8') as f:
# 读取文件内容为字符串
text = f.read()
# 对文本进行分词并去除长度为1的词和'高校'、'大学'两个词
words = []
for word in jieba.cut(text):
if len(word) > 1 and word not in ('高校', '大学'):
words.append(word)
# 统计词频并排序
word_counts = Counter(words)
sorted_word_counts = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
# 输出前20项
for word, count in sorted_word_counts[:20]:
print(f'{word}: {count}')
 系统已结题
6月14日
系统已结题
6月14日 已采纳回答
6月6日
已采纳回答
6月6日 请采纳用户回复
6月6日
请采纳用户回复
6月6日 请回答用户的提问
6月5日
请回答用户的提问
6月5日


