二分类研究,A类样本数322,B类样本数315,两类一共637,要计算的评价指标有准确率、灵敏度、特异性、F1分数。
十折交叉验证,是把样本分成10份,其中1份测试,9份训练。这样循环10次,每一次循环的时候,每一折的样本组成是十分之一✖322+十分之一✖315吗?还是直接十分之一×637呢?

十折交叉验证应用于二分类,关于样本数的组成问题

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

 关注
关注- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7670261
- 除此之外, 这篇博客: 李宏毅线性代数-基本概念中的 线性方程组是否有解,等价于,b是否是A的列向量的线性组合 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:

举例:1)b不是A的列向量的线性组合
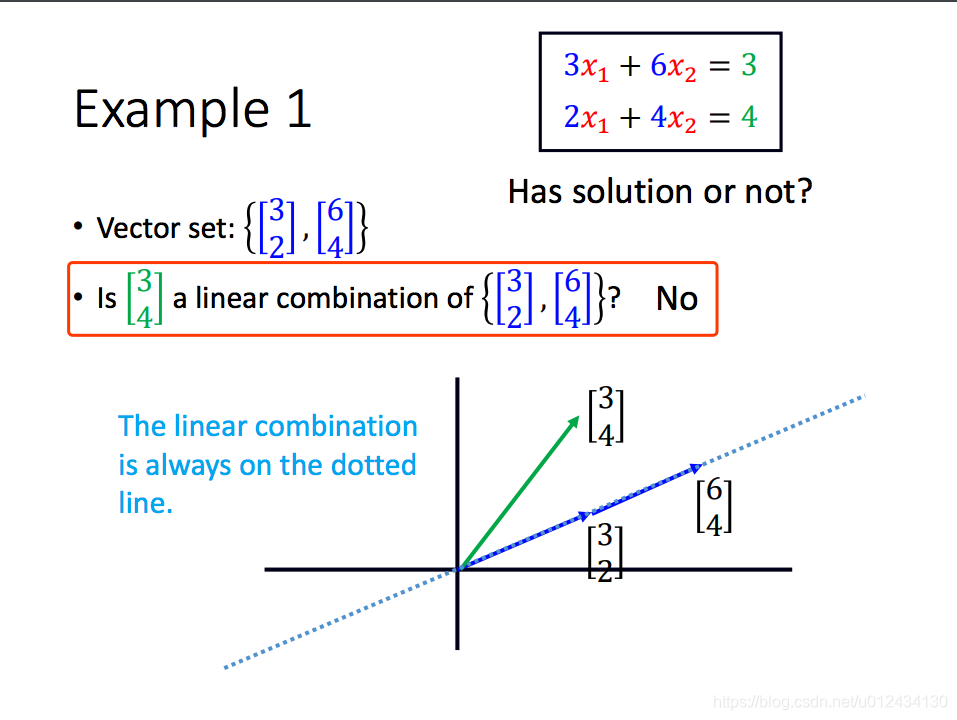
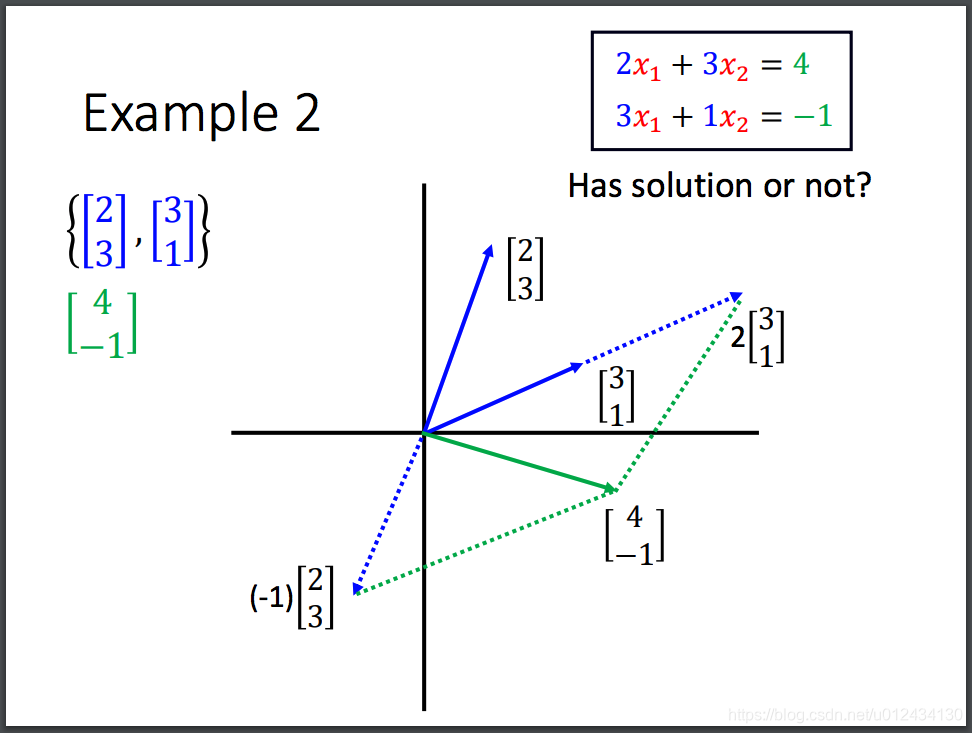
2)b是A的列向量的线性组合
- 以下回答由chatgpt基于相关博客总结生成:
问题提到了十折交叉验证中每个训练折的样本组成的计算方式。在十折交叉验证中,数据集被分为10个等分,每次用其中9个作为训练集,剩下的一个作为测试集。因此,每个训练折的样本数量应该是总样本数的十分之九。
具体计算方式为: - 首先,计算每个折的样本数量:总样本数除以10并取整。 - 然后,将计算出的每个折的样本数量乘以9,得到每个训练折的样本数量。
下面是示例代码,展示了如何计算每个训练折的样本数量:
import math total_samples = 637 num_folds = 10 fold_samples = math.floor(total_samples / num_folds) train_samples = fold_samples * (num_folds - 1)在这个例子中,
fold_samples表示每个折的样本数量,train_samples表示每个训练折的样本数量。可以看到,train_samples的计算方式是先计算每个折的样本数量,然后将其乘以9。所以答案是,每个训练折的样本组成是通过将每个折的样本数量乘以9来确定的。
解决 无用评论 打赏举报 分享
问题事件
 创建了问题
7月11日
创建了问题
7月11日
悬赏问题
- ¥15 关于#matlab#的问题:期望的系统闭环传递函数为G(s)=wn^2/s^2+2¢wn+wn^2阻尼系数¢=0.707,使系统具有较小的超调量
- ¥15 FLUENT如何实现在堆积颗粒的上表面加载高斯热源
- ¥30 截图中的mathematics程序转换成matlab
- ¥15 动力学代码报错,维度不匹配
- ¥15 Power query添加列问题
- ¥50 Kubernetes&Fission&Eleasticsearch
- ¥15 報錯:Person is not mapped,如何解決?
- ¥15 c++头文件不能识别CDialog
- ¥15 Excel发现不可读取的内容
- ¥15 关于#stm32#的问题:CANOpen的PDO同步传输问题