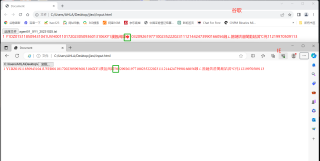
一个UTF-8的txt文件 前后是用GBK解析的,拿到的结果在谷歌和ie的结果不同;
解析完结果:
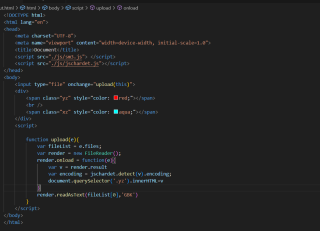
前端代码:

一个UTF-8的txt文件 前后是用GBK解析的,拿到的结果在谷歌和ie的结果不同;
解析完结果:
 分享
分享
你可以采用以下方法:
用jschardet自动检测编码:你已经在代码中引入了jschardet库,但实际上并没有使用它来检测文件的实际编码。通过用jschardet自动检测编码,你可以确保始终使用正确的编码来读取文件。
修改如下:
function upload(e) {
var fileList = e.files;
var render = new FileReader();
render.onload = function(e) {
var v = render.result;
var encoding = jschardet.detect(v).encoding;
if (encoding == 'UTF-8') {
render.readAsText(fileList[0], 'UTF-8');
} else {
document.querySelector('.yz').innerHTML = v;
}
}
render.readAsText(fileList[0], 'GBK');
}
确认你的文件确实是UTF-8编码:有时,文件可能看起来像UTF-8,但实际上可能使用了其他编码。确保文件确实是UTF-8编码的,可以避免解析问题。
手动设置编码选项:除了自动检测编码,你还可以为用户提供一个下拉列表,让他们手动选择要使用的编码(例如GBK、UTF-8等)。
尝试其他字符编码库:可能是由于浏览器或库之间的差异导致的。可以考虑使用其他的字符编码转换库,例如iconv-lite-js。
测试在多个浏览器上:确保你的解决方案在所有主要的浏览器(如Chrome、Firefox、IE、Edge等)上都可以工作。
分享 系统已结题
11月4日
系统已结题
11月4日 创建了问题
10月27日
创建了问题
10月27日



