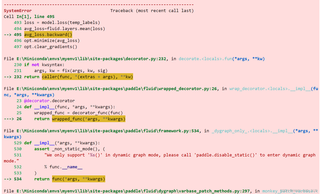
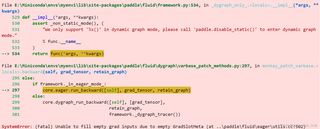
想问一下为什么复制paddle上的公开项目到本地运行,就出现了下面的报错,在AI studio直接运行就不会报错?
原项目地址:我发现了一篇高质量的实训项目,使用免费算力即可一键运行,还能额外获取8小时免费GPU运行时长,快来Fork一下体验吧。
胶囊神经网络paddle版实现(Capsule Network)(动态图):https://aistudio.baidu.com/projectdetail/657114?channel=0&channelType=0&sUid=939258&shared=1&ts=1704640503356
代码:
'''
@paddle实现完整代码
@author Reatris
使用minst数据集
'''
import numpy as np
import paddle
import paddle.fluid as fluid
import sys,os
import matplotlib.pylab as plt
from PIL import Image
import cv2
train_params = {
'batch_size':32,
'epoch_num':2,
'save_model_name':'Capnet_class_and_rebuild',
'm_plus':0.9,#计算损失值时大于这个值则loss=0
'm_det':0.1,#计算损失值时大于这个值则loss=0
'lambda_val':0.5,#错误概率loss权重
'build_loss_scale':0.0005,#decode损失scale
'with_decode':True,#是否训练decode部分
'train_comparison':False,#是否使用CNN+POOL网络对比
'challenge':False,#是否在训练过程中改变输入图片
'train_data':'mnist',#'可以选择mnist'或者'cat12'数据集
}
class Capsule_Layer(fluid.dygraph.Layer):
def __init__(self,pre_cap_num,pre_vector_units_num,cap_num,vector_units_num,use_Gaussian_distribution=False):
'''
胶囊层的实现类,可以直接同普通层一样使用
Args:
pre_vector_units_num(int):输入向量维度
vector_units_num(int):输出向量维度
pre_cap_num(int):输入胶囊数
cap_num(int):输出胶囊数
routing_iters(int):路由迭代次数,建议3次
Notes:
胶囊数和向量维度影响着性能,可作为主调参数
'''
super(Capsule_Layer,self).__init__()
self.use_Gaussian_distribution = use_Gaussian_distribution
self.routing_iters = 3
self.pre_cap_num = pre_cap_num
self.cap_num = cap_num
self.pre_vector_units_num = pre_vector_units_num
self.vector_units_num = vector_units_num
for j in range(self.cap_num):
self.add_sublayer('u_hat_w'+str(j),fluid.dygraph.Linear(\
input_dim=pre_vector_units_num,output_dim=vector_units_num))
def squash(self,vector):
'''
压缩向量的函数,类似激活函数,向量归一化
Args:
vector:一个4维张量 [batch_size,vector_num,vector_units_num,1]
Returns:
一个和x形状相同,长度经过压缩的向量
输入向量|v|(向量长度)越大,输出|v|越接近1
'''
vec_abs = fluid.layers.sqrt(fluid.layers.reduce_sum(fluid.layers.square(vector))) # 一个标量|v|模长度
scalar_factor = fluid.layers.square(vec_abs) / (1 + fluid.layers.square(vec_abs))
vec_squashed = scalar_factor * fluid.layers.elementwise_div(vector, vec_abs) # 对应元素相除
return(vec_squashed)
def capsule(self,x,B_ij,j,pre_cap_num):
'''
这是动态路由算法的精髓。
Args:
x:输入向量,一个四维张量 shape = (batch_size,pre_cap_num,pre_vector_units_num,1)
B_ij: shape = (1,pre_cap_num,cap_num,1)路由分配权重,这里将会选取(split)其中的第j组权重进行计算
j:表示当前计算第j个胶囊的路由
pre_cap_num:输入胶囊数
Returns:
v_j:经过多次路由迭代之后输出的4维张量(单个胶囊)
B_ij:计算完路由之后又拼接(concat)回去的权重
Notes:
B_ij,b_ij,C_ij,c_ij注意区分大小写哦
'''
x = fluid.layers.reshape(x,(x.shape[0],pre_cap_num,-1))
u_hat = getattr(self,'u_hat_w'+str(j))(x)
u_hat = fluid.layers.reshape(u_hat,(x.shape[0],pre_cap_num,-1,1))
shape_list = B_ij.shape#(1,1152,10,1)
split_size = [j,1,shape_list[2]-j-1]#取出当前加权项
for i in range(self.routing_iters):
C_ij = fluid.layers.softmax(B_ij,axis=2)
b_il,b_ij,b_ir = fluid.layers.split(B_ij,split_size,dim=2)#b_il是已经完成分配的项
c_il,c_ij,b_ir = fluid.layers.split(C_ij,split_size,dim=2)
v_j = fluid.layers.elementwise_mul(u_hat,c_ij)#加权[1,1152,1,1]x[32,1152,16,1]-->每16个向量分配一个权重
v_j = fluid.layers.reduce_sum(v_j,dim=1,keep_dim=True)#分配到同一个路由的向量相加[32,1,16,1]
v_j = self.squash(v_j) #[32,1,16,1]
v_j_expand = fluid.layers.expand(v_j,(1,pre_cap_num,1,1))#平铺[32,1,16,1]-->[32,1152,16,1]
u_v_produce = fluid.layers.elementwise_mul(u_hat,v_j_expand)#求内积
u_v_produce = fluid.layers.reduce_sum(u_v_produce,dim=2,keep_dim=True) #[32,1152,16,1]-->[32,1152,1,1]
b_ij += fluid.layers.reduce_sum(u_v_produce,dim=0,keep_dim=True)#内积累加,更新路由权重BIJ
B_ij = fluid.layers.concat([b_il,b_ij,b_ir],axis=2)
return v_j,B_ij
def forward(self,x):
'''
Args:
x:shape = (batch_size,pre_caps_num,vector_units_num,1) or (batch_size,C,H,W)
如果是输入是shape=(batch_size,C,H,W)的张量,
则将其向量化shape=(batch_size,pre_caps_num,vector_units_num,1)
满足:C * H * W = vector_units_num * caps_num
其中 C >= caps_num
Returns:
capsules:一个包含了caps_num个胶囊的list
'''
if x.shape[3]!=1:
x = fluid.layers.reshape(x,(x.shape[0],self.pre_cap_num,-1))
temp_x = fluid.layers.split(x,self.pre_vector_units_num,dim=2)
temp_x = fluid.layers.concat(temp_x,axis=1)
x = fluid.layers.reshape(temp_x,(x.shape[0],self.pre_cap_num,-1,1))
x = self.squash(x)
B_ij = fluid.layers.ones((1,x.shape[1],self.cap_num,1),dtype='float32')/self.cap_num#路由分配权重[1,1152,10,1]
capsules = []
for j in range(self.cap_num):
cap_j,B_ij = self.capsule(x,B_ij,j,self.pre_cap_num)#进行路由分配
capsules.append(cap_j)
capsules = fluid.layers.concat(capsules,axis=1)
return capsules
class Capconv_Net(fluid.dygraph.Layer):
def __init__(self,train_data='mnist'):
'''
Args:
decode_layer_num:decode部分的全连接层层数,用于遍历
self.caps_0:这个是实例化了定义的Capsule_Layer,用法和其他层基本相同
Notes:
这里只用了一个胶囊层,不知道叠加层数会如何
'''
super(Capconv_Net,self).__init__()
self.decode_layer_num = 3
self.train_data = train_data
if(train_data=='mnist'):
self.add_sublayer('conv0',fluid.dygraph.Conv2D(\
num_channels=1,num_filters=32,filter_size=(9,9),padding=0,stride = 1,act='relu'))
self.add_sublayer('conv1',fluid.dygraph.Conv2D(\
num_channels=32,num_filters=512,filter_size=(9,9),padding=0,stride = 2,act='relu'))
self.caps_0 = Capsule_Layer(72,256,10,32)#胶囊层
self.add_sublayer('rebuid_fc0',fluid.dygraph.Linear(input_dim=32,output_dim=512))
self.add_sublayer('rebuid_fc1',fluid.dygraph.Linear(input_dim=512,output_dim=1024))
self.add_sublayer('rebuid_fc2',fluid.dygraph.Linear(input_dim=1024,output_dim=784))
else:
self.conv0=fluid.dygraph.Conv2D(num_channels=3,num_filters=64,filter_size=(3,3),stride=1,padding=1,act='relu')
self.pool0 = fluid.dygraph.Pool2D(pool_size=2,pool_stride=2,pool_type='max')#32,256
self.conv1=fluid.dygraph.Conv2D(num_channels=64,num_filters=128,filter_size=(3,3),stride=1,padding=1,act='relu')
self.pool1 = fluid.dygraph.Pool2D(pool_size=2,pool_stride=2,pool_type='max')#32,256
self.conv2=fluid.dygraph.Conv2D(num_channels=128,num_filters=256,filter_size=(3,3),stride=1,padding=1,act='relu')
self.pool2 = fluid.dygraph.Pool2D(pool_size=2,pool_stride=2,pool_type='max')#32,256
self.caps_0 = Capsule_Layer(784,256,12,32)
self.conv3=fluid.dygraph.Conv2D(num_channels=256,num_filters=512,filter_size=(3,3),stride=1,padding=1,act='relu')
self.pool3 = fluid.dygraph.Pool2D(pool_size=2,pool_stride=2,pool_type='max')#32,256
self.caps_1 = Capsule_Layer(196,512,12,32)#胶囊层
def get_loss_v(self,label):
'''
计算边缘损失
Args:
label:shape=(32,10) one-hot形式的标签
Notes:
这里我调用Relu把小于0的值筛除
m_plus:正确输出项的概率(|v|)大于这个值则loss为0,越接近则loss越小
m_det:错误输出项的概率(|v|)小于这个值则loss为0,越接近则loss越小
(|v|即胶囊(向量)的模长)
'''
max_l = fluid.layers.relu(train_params['m_plus'] - self.output_caps_v_lenth)#广播
max_l = fluid.layers.reshape(fluid.layers.square(max_l),(train_params['batch_size'],-1))#32,10
max_r = fluid.layers.relu(self.output_caps_v_lenth - train_params['m_det'])
max_r = fluid.layers.reshape(fluid.layers.square(max_r),(train_params['batch_size'],-1))#32,10
margin_loss = fluid.layers.elementwise_mul(label,max_l)\
+ fluid.layers.elementwise_mul(1-label,max_r)*train_params['lambda_val']
self.margin_loss = fluid.layers.reduce_mean(margin_loss,dim=1)
def loss(self,label):
'''
计算边缘损失和decode
Args:
label:shape=(32,10) one-hot形式的标签
Returns:
total_loss or margin(不训练decode部分时)
Notes:
decode重建图像的损失用欧式距离计算
'''
self.get_loss_v(label)
if train_params['with_decode']:
euclidean_metric = fluid.layers.square(self.decode_result - self.input_imgs)#求得欧式距离
self.reconstruction_err = fluid.layers.mean(euclidean_metric)
self.total_loss = self.margin_loss + self.reconstruction_err * train_params['build_loss_scale']
return self.total_loss #返回总loss
else:
return self.margin_loss #只返回边缘loss
#只返回decode loss 冻结之后用
def accuracy(self,label):
label = fluid.layers.argmax(label,axis=1)
T_L = fluid.layers.reshape(self.argmax_idx,(label.shape[0],))
mask = paddle.fluid.layers.equal(T_L,label)
mask = np.argwhere(mask.numpy()==True)
return len(mask)/label.shape[0]
def forward(self,x):
if self.train_data == 'mnist':
if train_params['with_decode']:
self.input_imgs = fluid.layers.reshape(x,(train_params['batch_size'],-1))
x = self.conv0(x)
x = self.conv1(x)
self.output_caps = self.caps_0(x)# 32,10,16,1
self.output_caps_v_lenth = fluid.layers.sqrt(fluid.layers.reduce_sum(\
fluid.layers.square(self.output_caps),dim=2,keep_dim=True))##计算模长32,10,1,1
softmax_v = fluid.layers.softmax(self.output_caps_v_lenth,axis=1)#计算每个胶囊类概率 32,10,1,1
argmax = fluid.layers.argmax(softmax_v,axis=1)#选取最大概率索引32,1,1
mask_v = []
self.argmax_idx = fluid.layers.reshape(argmax,(argmax.shape[0],1))
if train_params['with_decode']:
######下面是decode部分######
#选取正确胶囊
for i in range(train_params['batch_size']):
v = self.output_caps[i][self.argmax_idx[i],:]
mask_v.append(fluid.layers.reshape(v,(1,self.output_caps.shape[2])))
self.mask_v = fluid.layers.concat(mask_v,axis=0)#32,16
#全连接层重构图像
x = self.mask_v
for i in range(self.decode_layer_num):
x = getattr(self,'rebuid_fc'+str(i))(x)
self.decode_result = x
else:
capsule_list = []
for i in range(4):
x = getattr(self,'conv'+str(i))(x)
x = getattr(self,'pool'+str(i))(x)
if i>1:
capsule_list.append(x)
output_cap_list = []
for j in range(2):
# print(capsule_list[j+1].shape)
output_cap_list.append(getattr(self,'caps_'+str(j))(capsule_list[j]))
self.output_caps = fluid.layers.concat(output_cap_list,axis=2)
# print(self.output_caps.shape)
self.output_caps_v_lenth = fluid.layers.sqrt(fluid.layers.reduce_sum(\
fluid.layers.square(self.output_caps),dim=2,keep_dim=True))##计算模长32,10,1,1
softmax_v = fluid.layers.softmax(self.output_caps_v_lenth,axis=1)#计算每个胶囊类概率 32,10,1,1
argmax = fluid.layers.argmax(softmax_v,axis=1)#选取最大概率索引32,1,1
mask_v = []
self.argmax_idx = fluid.layers.reshape(argmax,(32,1))
#用同规模卷积神经网络+池化层对比
class Mnistnet(fluid.dygraph.Layer):
def __init__(self,train_data='mnist'):
super(Mnistnet,self).__init__()
self.train_data = train_data
if(train_data=='mnist'):
self.add_sublayer('conv0',fluid.dygraph.Conv2D(\
num_channels=1,num_filters=32,filter_size=(9,9),padding=0,stride = 1,act='relu'))
self.add_sublayer('conv1',fluid.dygraph.Conv2D(\
num_channels=32,num_filters=512,filter_size=(9,9),padding=0,stride = 2,act='relu'))
self.pool = fluid.dygraph.Pool2D(global_pooling=True,pool_type='max')#32,256
self.fc0=fluid.dygraph.Linear(input_dim=512,output_dim=128,act='relu')#[32,256] ==> [32,50]
self.fc2=fluid.dygraph.Linear(input_dim=128,output_dim=10,act='softmax')
else:
self.block1_conv1_3_64=fluid.dygraph.Conv2D(num_channels=3,num_filters=64,filter_size=(3,3),stride=1,padding=1,act='relu')
self.pool0 = fluid.dygraph.Pool2D(pool_size=2,pool_stride=2,pool_type='max')#32,256
self.block1_conv2_3_64=fluid.dygraph.Conv2D(num_channels=64,num_filters=128,filter_size=(3,3),stride=1,padding=1,act='relu')
self.pool1 = fluid.dygraph.Pool2D(pool_size=2,pool_stride=2,pool_type='max')#32,256
self.block2_conv1_3_128=fluid.dygraph.Conv2D(num_channels=128,num_filters=256,filter_size=(3,3),stride=1,padding=1,act='relu')
self.pool2 = fluid.dygraph.Pool2D(pool_size=2,pool_stride=2,pool_type='max')#32,256
self.block2_conv2_3_128=fluid.dygraph.Conv2D(num_channels=256,num_filters=512,filter_size=(3,3),stride=1,padding=1,act='relu')
self.g_poo1 = fluid.dygraph.Pool2D(global_pooling=True,pool_type='max')
self.fc0 = fluid.dygraph.Linear(input_dim=896,output_dim=256,act='relu')
self.fc1 = fluid.dygraph.Linear(input_dim=256,output_dim=12,act='softmax')
def forward(self,x):
if self.train_data =='mnist':
for layers in self.sublayers():
x = layers(x)
x = fluid.layers.squeeze(x,axes=[])
return x
else:
x =self.block1_conv1_3_64(x)
x = self.pool0(x)
x = self.block1_conv2_3_64(x)
x = self.pool1(x)
f1 = fluid.layers.squeeze(self.g_poo1(x),axes=[])
x = self.block2_conv1_3_128(x)
x = self.pool2(x)
f2 = fluid.layers.squeeze(self.g_poo1(x),axes=[])
x = self.block2_conv2_3_128(x)
f3 = fluid.layers.squeeze(self.g_poo1(x),axes=[])
x = fluid.layers.concat((f1,f2,f3),axis=1)
x = self.fc0(x)
x = self.fc1(x)
return x
#猫12分类数据读取
def data_load(train_list_path,batch_size):
'''
train_list_path:标注文件txt所在path
'''
train_dir_list=[]
train_label=[]
with open(train_list_path,'r') as train_dirs:
#train_dir_list.append(train_dirs.readline())
lines=[line.strip() for line in train_dirs]
for line in lines:
img_path,label=line.split()
train_dir_list.append(img_path)
train_label.append(label)
def reader():
imgs=[]
labels=[]
img_mask=np.arange(len(train_dir_list)) #生成索引
np.random.shuffle(img_mask) #随机打乱索引
count=0
for i in img_mask:
img=cv2.imread(train_dir_list[i])
img=cv2.resize(img,(224,224),interpolation=cv2.INTER_CUBIC)/255
img=np.transpose(img,(2,0,1))
imgs.append(img)
temp_labels_one_hot = np.zeros(12)
temp_labels_one_hot[int(train_label[i])] = 1
labels.append(temp_labels_one_hot)
count+=1
if(count%train_params['batch_size']==0):
yield np.asarray(imgs).astype('float32'),np.asarray(labels).astype('float32').reshape((train_params['batch_size'],12))
imgs=[]
labels=[]
return reader
def draw_train_process(iters,accs_mnist,loss_mnist,accs,loss):
'''
训练可视化(对比)
'''
plt.title('CapsulesNet training',fontsize=24)
plt.xlabel('iters',fontsize=20)
plt.ylabel('acc/loss',fontsize=20)
plt.plot(iters,loss_mnist,color='yellow',label='loss_of_cnn+pool')
plt.plot(iters,accs_mnist,color='blue',label='accuracy_cnn+pool')
plt.plot(iters,accs,color='red',label='accuracy_capsules_net')
plt.plot(iters,loss,color='green',label='loss_of_capsule_net')
plt.legend()
plt.grid()
plt.show()
def draw_train_process2(iters,accs,loss):
'''
训练可视化
'''
plt.title('CapsulesNet training',fontsize=24)
plt.xlabel('iters',fontsize=20)
plt.ylabel('acc/loss',fontsize=20)
plt.plot(iters,accs,color='red',label='accuracy')
plt.plot(iters,loss,color='green',label='loss')
plt.legend()
plt.grid()
plt.show()
def fix_value(img_pixs):#像素拉伸
'''
img_pixs:featuremap的像素矩阵
'''
pix_max=np.max(img_pixs)#取最大像素
pix_min=np.min(img_pixs)#取最小像素
pix_range=np.abs(pix_max)+np.abs(pix_min)#获取像素距离
if(pix_range==0): #如果所有值都是零则直接返回(下面不能除以零)
return img_pixs
pix_rate = 255/pix_range#获取像素缩放倍率
pix_left = pix_min*pix_rate#获取最小还原像素值
img_pixs = img_pixs*pix_rate-pix_left#整体像素值平移
img_pixs[np.where(img_pixs<0)]=0. #增加鲁棒性,检查超出区间的像素值,np.where(a<x)与a<x等同
img_pixs[np.where(img_pixs>255)]=255.
return img_pixs
def show_array2img(array,title):
rebuilded_img = Image.fromarray(array.astype('uint8')).convert('RGB')
plt.imshow(rebuilded_img)
plt.title(title)
plt.show()
with fluid.dygraph.guard():
if train_params['train_data']=='mnist':
train_reader = paddle.batch(reader=paddle.reader.shuffle(\
paddle.dataset.mnist.train(),buf_size=512),batch_size=train_params['batch_size'])
else:
train_reader = data_load('train_list.txt',train_params['batch_size'])
if train_params['train_comparison']:
train_params['with_decode']=False#对比时就不训练decode部分了
print('start training CNN+POOL net')
model_mnist=Mnistnet(train_params['train_data'])
model_mnist.train()
if train_params['train_data']=='mnist':
opt_mnist=fluid.optimizer.AdamOptimizer(learning_rate=0.01,parameter_list=model_mnist.parameters())
checkpoint=train_params['epoch_num']*1876*0.5
else:
opt_mnist=fluid.optimizer.AdamOptimizer(learning_rate=0.001,parameter_list=model_mnist.parameters())
checkpoint=train_params['epoch_num']*68*0.5
epoch_num_mnist = train_params['epoch_num']
all_train_costs_mnist = []
all_train_accs_mnist = []
all_iter = 0
for pass_num_mnist in range(epoch_num_mnist):
for batch_id_mnist,data in enumerate(train_reader()):
if train_params['train_data']=='mnist':
temp_images = []
temp_labels = []
for i in range(32):
if(all_iter>checkpoint and train_params['challenge']):
temp_images.append(np.transpose(np.reshape(data[i][0],(1,28,28)),(0,2,1)))
else:
temp_images.append(np.reshape(data[i][0],(1,28,28)))
temp_labels.append(data[i][1])
temp_images=fluid.dygraph.to_variable(np.asarray(temp_images).reshape((32,1,28,28)))
temp_labels=fluid.dygraph.to_variable(np.asarray(temp_labels).reshape((32,1)))
else:
temp_images,temp_labels = data
if(all_iter>checkpoint and train_params['challenge']):
temp_images=fluid.dygraph.to_variable(np.transpose(\
np.asarray(temp_images).reshape((32,3,224,224)),(0,1,3,2)))
else:
temp_images=fluid.dygraph.to_variable(np.asarray(temp_images).reshape((32,3,224,224)))
temp_labels=fluid.dygraph.to_variable(np.asarray(temp_labels).reshape((32,12)))
temp_labels = fluid.layers.reshape(fluid.layers.argmax(temp_labels,axis=1),(32,1))
predict = model_mnist(temp_images)
#计算loss
loss_mnist= fluid.layers.cross_entropy(label=temp_labels,input=predict)
#计算accuracy
acc_mnist=fluid.layers.accuracy(input=predict,label=temp_labels)
avg_loss_mnist = fluid.layers.mean(loss_mnist)
avg_loss_mnist.backward()#反向传播跟新weights
opt_mnist.minimize(avg_loss_mnist)
opt_mnist.clear_gradients()
all_iter +=1
if all_iter%100==0:
all_train_costs_mnist.append(avg_loss_mnist.numpy()[0])
all_train_accs_mnist.append(acc_mnist.numpy()[0])
print('pass_num:{},iters:{},loss:{},acc:{}'.format(\
pass_num_mnist,all_iter,avg_loss_mnist.numpy()[0],acc_mnist.numpy()[0]))
print("Final loss of cnn+pool: {}".format(avg_loss_mnist.numpy()))
print('start training CNN+Capsules')
model = Capconv_Net(train_params['train_data']) #实列化模型
if os.path.exists(train_params['save_model_name'] + '.pdparams') and not train_params['train_comparison']:#存在模型参数则继续训练
print('continue training')
param_dict,_ = fluid.dygraph.load_dygraph(train_params['save_model_name'])
model.load_dict(param_dict)
model.train()
all_iter = 0
all_loss = []
all_iters = []
all_accs = []
if train_params['train_data']=='mnist':
opt=fluid.optimizer.AdamOptimizer(learning_rate=0.01,parameter_list=model.parameters())
checkpoint=train_params['epoch_num']*1876*0.5
else:
opt=fluid.optimizer.AdamOptimizer(learning_rate=0.001,parameter_list=model.parameters())
checkpoint=train_params['epoch_num']*68*0.5
for pass_num in range(train_params['epoch_num']):
for pass_id,data in enumerate(train_reader()):
if train_params['train_data']=='mnist':
temp_images = []
temp_labels = []
for i in range(32):
if(all_iter>checkpoint and train_params['challenge']):
temp_images.append(np.transpose(np.reshape(data[i][0],(1,28,28)),(0,2,1)))
else:
temp_images.append(np.reshape(data[i][0],(1,28,28)))
temp_labels_one_hot = np.zeros(10)
temp_labels_one_hot[data[i][1]] = 1
temp_labels.append(temp_labels_one_hot)
temp_images = fluid.dygraph.to_variable(np.asarray(temp_images))#转换成tensor才能输入
temp_labels = fluid.dygraph.to_variable(\
np.asarray(temp_labels).reshape((32,10)).astype('float32'))
else:
temp_images,temp_labels = data
if(all_iter>checkpoint and train_params['challenge']):
temp_images=fluid.dygraph.to_variable(np.transpose(\
np.asarray(temp_images).reshape((32,3,224,224)),(0,1,3,2)))
else:
temp_images=fluid.dygraph.to_variable(np.asarray(temp_images).reshape((32,3,224,224)))
temp_labels=fluid.dygraph.to_variable(np.asarray(temp_labels).reshape((32,12)))
model(temp_images)
loss = model.loss(temp_labels)
avg_loss=fluid.layers.mean(loss)
avg_loss.backward()
opt.minimize(avg_loss)
opt.clear_gradients()
all_iter+=1
if all_iter%100==0:
acc=model.accuracy(temp_labels)
all_loss.append(avg_loss.numpy()[0])
all_iters.append(all_iter)
all_accs.append(acc)
print('pass_epoch:{},iters:{},loss:{},acc:{}'.format(pass_num,all_iter,avg_loss.numpy()[0],acc))
fluid.save_dygraph(model.state_dict(),train_params['save_model_name']) #保存模型参数
if train_params['train_comparison']:
draw_train_process(all_iters,all_train_accs_mnist,all_train_costs_mnist,all_accs,all_loss)
else:
draw_train_process2(all_iters,all_accs,all_loss)
print('finished training')
if train_params['with_decode']:
#图像重构显示
show_array2img(fix_value(np.reshape(model.input_imgs[0].numpy(),(28,28))),'imput_img')
show_array2img(fix_value(np.asarray(np.reshape(model.decode_result[0].numpy(),(28,28)))),'rebuild_img')