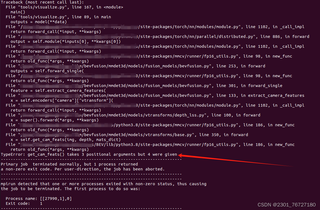
请问大家在bevfusion-mit复现时的可视化有没有成功?
我在运行其可视化代码torchpack dist-run -np 1 python tools/visualize.py configs/nuscenes/det/transfusion/secfpn/camera+lidar/swint_v0p075/convfuser.yaml --mode pred --checkpoint pretrained/bevfusion-det.pth --bbox-score 0.2 --out-dir vis_result
时会出现下面的报错,请问有什么解决方案?