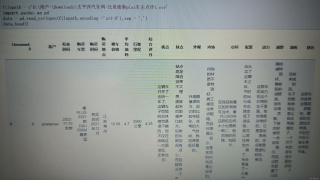
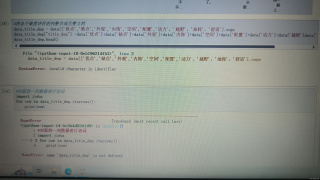
如图,想要将csv文件内{优点,缺点,外观,内饰,空间,配置,动力,越野,油耗,舒适}这些并为一个文档,便于后续的jieba文本分词
涉及的板块应该是文本分析
使用的是anaconda自带的juypter notebook

如图,想要将csv文件内{优点,缺点,外观,内饰,空间,配置,动力,越野,油耗,舒适}这些并为一个文档,便于后续的jieba文本分词
涉及的板块应该是文本分析
使用的是anaconda自带的juypter notebook
 分享
分享
以下内容由CHATGPT及阿里嘎多学长共同生成、有用望采纳:
根据您提供的链接内容,您想要实现的功能是提取CSV文件中的特定列,将这些列整合为一篇文档,并使用jieba库进行中文分词。以下是实现这一功能的示例代码:
首先,您需要安装pandas和jieba库,如果尚未安装,可以使用以下命令安装:
pip install pandas jieba
接下来,是实现功能的示例代码:
import pandas as pd
import jieba
# 读取CSV文件
df = pd.read_csv('your_file.csv')
# 假设CSV文件中包含的列名是'优点', '缺点', '外观', '内饰', '空间', '配置', '动力', '越野', '油耗', '舒适'
columns_to_extract = ['优点', '缺点', '外观', '内饰', '空间', '配置', '动力', '越野', '油耗', '舒适']
# 提取特定列
extracted_data = df[columns_to_extract]
# 将提取的数据整合为一篇文档
document = ' '.join(extracted_data.astype(str).values.flatten())
# 使用jieba进行分词
words = jieba.cut(document, cut_all=False)
# 将分词结果转换为一个列表
word_list = list(words)
# 打印分词结果
print(word_list)
# 如果需要去除停用词,可以加载停用词表并过滤掉停用词
# 停用词表可以在网上找到,或者自定义一个
stopwords = set(['的', '和', '是']) # 示例停用词表,实际应用中需要更全面的停用词表
filtered_words = [word for word in word_list if word not in stopwords]
# 打印去除停用词后的分词结果
print(filtered_words)
请注意,您需要将 'your_file.csv' 替换为您的CSV文件的实际路径。此外,您可能需要根据实际情况调整停用词表。
这个示例代码首先使用pandas读取CSV文件,然后提取指定的列,将这些列的数据整合为一篇文档。接着,使用jieba进行分词,并将分词结果输出为列表。最后,您可以根据需要加载停用词表并过滤掉停用词。
分享 系统已结题
4月26日
系统已结题
4月26日 已采纳回答
4月18日
创建了问题
4月18日
已采纳回答
4月18日
创建了问题
4月18日



