识别功能无法使用,无法获取有效标签,从第六位开始,预测标签全为-1
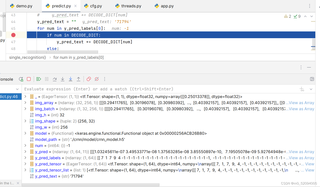

识别功能无法使用,无法获取有效标签,从第六位开始,预测标签全为-1
 分享
分享
 关注
关注引自免费微信小程序:皆我百晓生
看起来你在使用一个基于深度学习的OCR(光学字符识别)模型进行文字识别,但是遇到了一个问题,预测标签中出现了-1,这通常意味着在解码字典(DECODE_DICT)中没有找到对应的索引。要解决这个问题,我们需要检查几个可能的原因:
DECODE_DICT是否包含所有的可能预测值。DECODE_DICT的索引范围匹配。首先,你需要确保DECODE_DICT包含了所有可能的字符标签。对于CTC(Connectionist Temporal Classification)模型,它可能会输出一些特殊标记,例如-1(通常表示空字符),以及其他用于处理序列对齐的辅助标记。这些特殊标记可能不在标准的字母数字字符集中。为了修复这个问题,你需要创建一个包含所有可能输出的字典,包括这些特殊标记。
你可以尝试创建一个新的字典,例如EXTENDED_DECODE_DICT,它应该包含DECODE_DICT中的所有元素,并添加额外的键值对,比如{-1: 'special_char'}或者其他可能的特殊标记。
以下是修改后的代码片段,展示了如何创建EXTENDED_DECODE_DICT:
# 假设DECODE_DICT已经定义
EXTENDED_DECODE_DICT = {}
EXTENDED_DECODE_DICT.update(DECODE_DICT)
EXTENDED_DECODE_DICT[-1] = 'special_char' # 添加特殊的-1标记
# 在你的代码中替换DECODE_DICT为EXTENDED_DECODE_DICT
for num in y_pred_Labels[0]:
if num in EXTENDED_DECODE_DICT:
y_pred_text += EXTENDED_DECODE_DICT[num]
else:
y_pred_text += EXTENDED_DECODE_DICT[-1] # 如果找不到,使用'special_char'
这样,即使遇到未在原始字典中定义的预测值,也会被正确地转换为字符串。注意,如果你的模型有其他特定的特殊标记,你需要将它们也加入到EXTENDED_DECODE_DICT中。
另外,确保你的模型输出的维度和DECODE_DICT的大小是一致的。如果模型输出的维度大于DECODE_DICT的长度,那么DECODE_DICT[num]会抛出KeyError,因为索引超出了字典的范围。在这种情况下,你应该调整模型的输出尺寸,或者扩展DECODE_DICT以适应更大的输出。
如果以上建议仍然无法解决问题,那么你可能需要提供更多的上下文信息,以便更准确地诊断问题。例如,分享模型结构、训练配置以及数据预处理的细节可能会有所帮助。
分享 创建了问题
4月23日
创建了问题
4月23日

