编写好MapReduce程序运行主类InvertedIndexDiver,结果如下
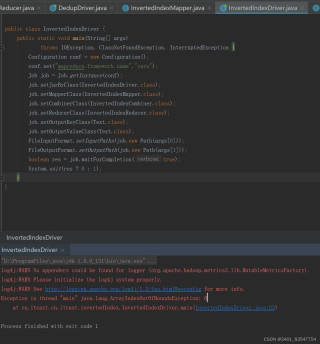
在hadoop1执行如下命令运行MapReduce程序,结果如下

HDFS Web UI界面也查不到运行结果

编写好MapReduce程序运行主类InvertedIndexDiver,结果如下
 分享
分享
以下内容由CHATGPT及阿里嘎多学长共同生成、有用望采纳:
InvertedIndexDriver类的main方法。该方法配置了一个MapReduce作业,设置了框架为YARN,指定了作业的jar文件、Mapper、Combiner、Reducer类,以及输入输出键值类。然后设置了输入输出路径,并启动作业,等待完成。最后,程序捕获了ArrayIndexOutOfBoundsException异常,并以错误码1退出。InvertedIndexDriver类,这通常意味着类路径设置不正确或jar包中缺少该类。/user/root/Invertedindex/,其中包含一个名为input的文件夹。这个目录的权限、所有者、组和其他信息也被列出。用户试图运行一个MapReduce程序来实现倒排索引,但是在执行过程中遇到了几个错误,导致程序无法正常运行。用户希望解决的问题是如何成功运行这个MapReduce程序,并在HDFS Web UI界面上看到运行结果。
java.lang.ArrayIndexOutOfBoundsException通常发生在尝试访问数组中不存在的索引时。这可能是因为程序中存在逻辑错误,尝试访问args数组中不存在的元素。java.lang.ClassNotFoundException表明在运行时找不到InvertedIndexDriver类。这可能是因为jar包没有正确构建,或者在运行命令中没有指定包含该类的jar包。ArrayIndexOutOfBoundsException:检查main方法中的代码,确保在引用args数组之前对其进行了正确的检查和处理。hadoop jar命令,并确保指定了包含InvertedIndexDriver类的jar包。以下是修正后的InvertedIndexDriver类的示例代码:
public class InvertedIndexDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length < 2) {
System.err.println("Usage: InvertedIndexDriver <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "yarn");
Job job = Job.getInstance(conf);
job.setJarByClass(InvertedIndexDriver.class);
job.setMapperClass(InvertedIndexMapper.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
hadoop jar path_to_your_jar.jar InvertedIndexDriver /input/path /output/path
如果代码和环境配置正确,MapReduce作业将成功运行,最终在HDFS Web UI界面上可以看到输出目录/output/path下的结果文件。如果遇到错误,Hadoop会提供相应的错误信息,帮助进一步调试。
分享 debug调试无法运行 Method threw.Cannot evaluate org.apache.hadoop.mapreduce.Job.toString()
hadoop
mapreduce
大数据
有问必答
debug调试无法运行 Method threw.Cannot evaluate org.apache.hadoop.mapreduce.Job.toString()
hadoop
mapreduce
大数据
有问必答
 系统已结题
5月2日
系统已结题
5月2日 创建了问题
4月24日
创建了问题
4月24日


