YOLOv10训练好模型之后,进行验证发现labels中的txt文件全是300行,这与我想要的结果不相同
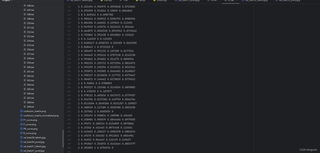

YOLOv10训练好模型之后,进行验证发现labels中的txt文件全是300行,这与我想要的结果不相同
 分享
分享
 关注
关注??上午好,题主!目前:??[在线]
??参考GPT-4o mini 模型、由清水白石008整理提供!
??今日金句:“苦难是人生的老师,通过苦难,走向欢乐。” —— 贝多芬
在使用 YOLOv10 进行模型训练后,如果在验证时发现 labels 文件夹中的 .txt 文件每个都有固定的 300 行数据,这通常意味着存在某些问题。以下是对可能原因的分析和解决步骤的详细说明:
过度生成空标签文件:
.txt 文件,存储该图像中的标注信息。如果出现空标签或无效标注,可能会导致每个标签文件生成过多的无意义行。数据预处理或导出问题:
导入数据时的配置问题:
.txt 文件中存在大量无效的标签行。数据生成器或脚本错误:
.txt 文件的格式.txt 文件应包含与图像中物体数量相对应的行,每一行代表一个标注数据,格式一般为:<class_id> <x_center> <y_center> <width> <height>
.txt 文件,检查是否存在多余的空行或重复的标注数据。.txt 文件中存在重复或空行,可以通过编写 Python 脚本来清理多余的数据。例如:import os
# 设置标签文件所在的路径
label_folder = 'path_to_labels_folder'
# 遍历所有标签文件
for label_file in os.listdir(label_folder):
if label_file.endswith('.txt'):
label_path = os.path.join(label_folder, label_file)
# 读取每个标签文件
with open(label_path, 'r') as f:
lines = f.readlines()
# 过滤掉空行或多余的行
valid_lines = [line for line in lines if line.strip() != '']
# 覆盖原始文件,保存有效行
with open(label_path, 'w') as f:
f.writelines(valid_lines)
data.yaml 文件中的类别数量(nc 参数)与实际类别匹配。.txt 文件中的标签数据格式正确,没有多余的空行或错误标注。通过逐步排查,你应该能够找到并解决问题。如果问题依然存在,可以详细描述你的数据处理流程,我可以帮你进一步分析。
分享 创建了问题
10月9日
创建了问题
10月9日

