
工具:CentOS7,Xshell,DataGrip
问题描述:在拍摄快照时,一切正常,也可以正常访问haproxy后台监控网址。用虚拟机拍摄快照之后,关机再开机,再次转到快照时,所有docker都为up状态,但是数据库全部断连。
问题背景:快照处是完成了“数据库集群的负载均衡”实验,NODE15为MySQL数据库PXC集群,即node1node5,HH1和HH2为负载均衡,即h1和h2
[root@localhost ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
629a85e90511 haproxy "docker-entrypoint.s…" 5 hours ago Up 5 hours 0.0.0.0:4004->3306/tcp, :::4004->3306/tcp, 0.0.0.0:4003->8888/tcp, :::4003->8888/tcp h2
a378b2275cdc haproxy "docker-entrypoint.s…" 5 hours ago Up 5 hours 0.0.0.0:4002->3306/tcp, :::4002->3306/tcp, 0.0.0.0:4001->8888/tcp, :::4001->8888/tcp h1
bf93f5dcfb32 pxc "/entrypoint.sh " 6 hours ago Up 6 hours 4567-4568/tcp, 0.0.0.0:3310->3306/tcp, :::3310->3306/tcp node5
f247eb1c6b35 pxc "/entrypoint.sh " 6 hours ago Up 6 hours 4567-4568/tcp, 0.0.0.0:3309->3306/tcp, :::3309->3306/tcp node4
47010444b080 pxc "/entrypoint.sh " 6 hours ago Up 6 hours 4567-4568/tcp, 0.0.0.0:3308->3306/tcp, :::3308->3306/tcp node3
dd671b1ef52b pxc "/entrypoint.sh " 6 hours ago Up 6 hours 4567-4568/tcp, 0.0.0.0:3307->3306/tcp, :::3307->3306/tcp node2
fd38cda72390 pxc "/entrypoint.sh " 6 hours ago Up 6 hours 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp, 4567-4568/tcp node1
07e290b63d62 java "bash" 6 hours ago Exited (0) 6 hours ago myjava3
[root@localhost ~]#
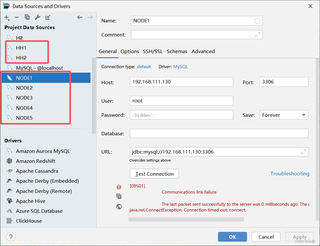
错误描述:
[08S01]
Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
java.net.ConnectException: Connection timed out: connect.
尝试:
1.服务处数据库一直是启动的
2.重启网络后,没有用
[root@localhost ~]# systemctl restart network
3.关闭防火墙,没有用
[root@localhost ~]# service firewalld stop
Redirecting to /bin/systemctl stop firewalld.service






